[TOC]
前言
此虚拟机并不是指VMware、Vbox等,而是指自己定义一套指令,在程序中能有一套函数和结构解释自己定义的指令并执行功能的一个程序。更确切的说是代码虚拟化。
虚拟机保护是一种基于虚拟机的代码保护技术。他将基于x86汇编系统中的可执行代码转换为字节码指令系统的代码。来达到不被轻易篡改和逆向的目的。
而在CTF中,VM就是出题人通过实现一个小型的虚拟机,把程序的代码转换为程序设计者自定义的操作码(opcode)然后在程序执行时通过解释操作码,执行对应的函数,从而实现程序原有的功能。
一般的虚拟机结构:
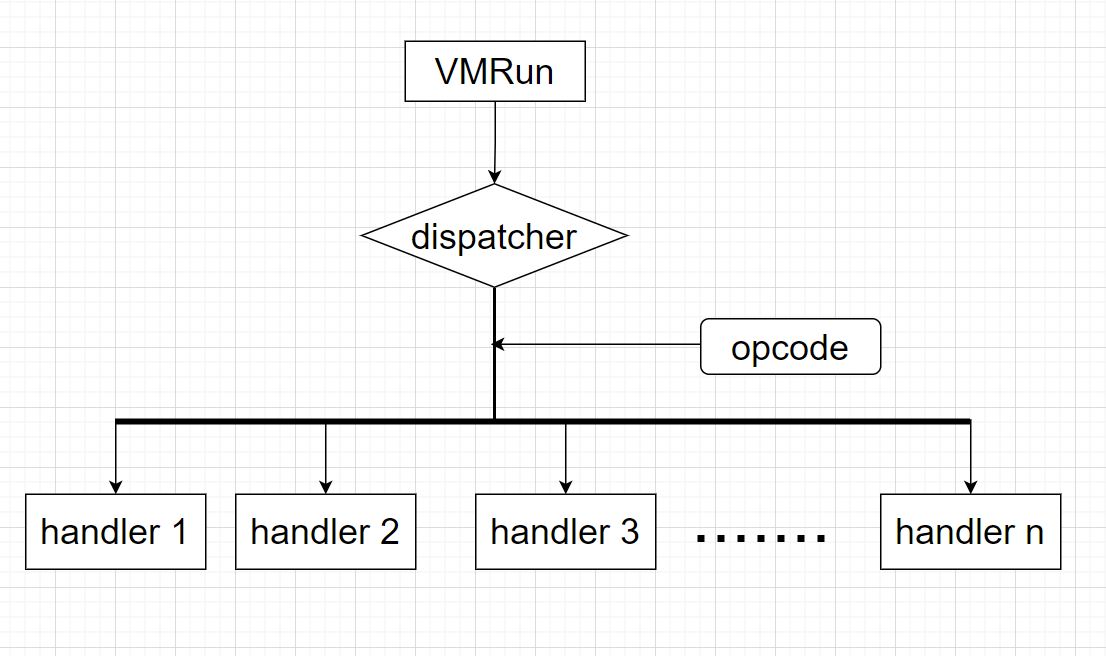
VMRun:虚拟机入口函数
dispatcher:调度器,用于解释opcode,并选择对应的handler函数执行,当handler执行完后会跳回这里,形成一个循环。
opcode:程序可执行代码转换成的操作码
handler:各种功能对象模块
CTF中VM的实现
其实要实现一个VM就是去实现上图的各个模块
- 定义一套opcode以及对应的handler
- 模拟cpu,寄存器和堆栈
- 把我们要实现的算法翻译成我们定义的opcode
我们接下来来实现一个简单的虚拟机:我们从我们最后实现的算法功能来定义我们需要的handler:
我们最后的算法功能是:
接收用户输入的45个字符,如果用户输入长度不足45则直接退出程序,否则对用户输入的每个字符tmp进行如下加密处理:
'a' <= tmp <= 'z' ==> tmp = tmp ^ 71; push tmp;
'A' <= tmp <= 'Z' ==> tmp = tmp ^ 75; push tmp;
'0' <= tmp <= '9' ==> tmp = '0' + 9 - (tmp - '0') ; push tmp;
others ==> push tmp;然后把加密后的字符串与正确的加密字符串比较,如果相等输出right,否则输出wrong
flag为:flag{Th1s_1s_A_VerY_EzVM_And_Y0u_Are_S0_g00d}
enc_flag为:encflag = [33, 43, 38, 32, 123, 31, 47, 56, 52, 95, 56, 52, 95, 10, 95, 29, 34, 53, 18, 95, 14, 61, 29, 6, 95, 10, 41, 35, 95, 18, 57, 50, 95, 10, 53, 34, 95, 24, 57, 95, 32, 57, 57, 35, 125]功能对应的伪C代码如下:
gets(input)
len = strlen(input)
if(len != 45)
exit;
for(int i = 0; i < input; i++){
if(input[i] >= 'a' && input[i] <= 'z'){
int tmp = input[i] ^ 71;
push(tmp);
} else if (input[i] >= 'A' && input[i] <= 'Z'){
int tmp = input[i] ^ 75;
push(tmp);
} else if (input[i] >= '0' && input[i] <= '9'){
int tmp = '0' + 9 - (input[i] - '0');
push(tmp);
} else push(input[i]);
}
for(int i = len-1; i>=0; i++){
int tmp = pop();
if(tmp != input[i]){
printf("wrong");
exit(0);
}
}
printf("right");上面伪C代码对应的伪汇编:
[1] call gets(input)
reg0 = strlen(input)
[2] mov reg1, 45
[3] cmp reg0, reg1
[4] je [7]
[5] printf("wrong")
[6] exit
[7] mov reg3, 0 ;reg3为input[i]中的i
[8] mov reg0, 45
[9] cmp reg3, reg0
[10] je [46]
[11] mov reg0, input[reg3]
[12] mov reg1, 'a'
[13] cmp reg0, reg1
[14] jl [21]
[15] mov reg1, 'z'
[16] cmp reg0, reg1
[17] jg [21]
[18] mov reg1, 71
[19] xor reg0, reg1
[20] jmp [42]
[21] mov reg1, 'A'
[22] cmp reg0, reg1
[23] jl [30]
[24] mov reg1, 'Z'
[25] cmp reg0, reg1
[26] jg [30]
[27] mov reg1, 75
[28] xor reg0, reg1
[29] jmp [42]
[30] mov reg1, '0'
[31] cmp reg0, reg1
[32] jl [42]
[33] mov reg1, '9'
[34] cmp reg0, reg1
[35] jg [42]
[36] mov reg1, '0'
[37] mov reg2, 9
[38] add reg1, reg2
[39] sub reg1, reg0
[40] mov reg0, '0'
[41] add reg0, reg1
[42] push reg0
[43] mov reg0, 1
[44] add reg3, reg0
[45] jmp [8]
[46] check()我们需要的汇编指令有:
1:mov reg, data
2:xor reg0, reg1
3:add reg0, reg1
4:sub reg0, reg1
5:push、6:pop
7:cmp reg0, reg1 ;我们把比较的结果放在eflag中
8:jmp、9:je、10:jne、11:jg、12:jl
这里我们在加一些指令:nop、printw、mov_input
需要的寄存器:reg0、reg1、reg2、reg3、eflag
我们还需要:stack、vm_sp、vm_ip为了方便跳转指令的实现,我们统一指令长度为3,正如计组里面所说:简单源于规整;具体代码就不放了,写的太烂了>_<框架如下
#include <iostream>
#include <string.h>
#define HandlerN 12
char enc_flag[] = {
33, 43, 38, 32, 123, 31, 47, 56, 52, 95,
56, 52, 95, 10, 95, 29, 34, 53, 18, 95,
14, 61, 29, 6, 95, 10, 41, 35, 95, 18,
57, 50, 95, 10, 53, 34, 95, 24, 57, 95,
32, 57, 57, 35, 125
};
char opcodes[] = {
11, 0, 0, 1, 1, 45, 7, 0, 1, 8, 7, 1,
9, 0, 0, 10, 0, 0, 1, 3, 0, 1, 0, 45,
7, 3, 0, 8, 46, 1, 12, 0, 3, 1, 1, 97,
7, 0, 1, 8, 21, 3, 1, 1, 122, 7, 0, 1,
8, 21, 4, 1, 1, 71, 2, 0, 1, 8, 42, 0,
1, 1, 65, 7, 0, 1, 8, 30, 3, 1, 1, 90,
7, 0, 1, 8, 30, 4, 1, 1, 75, 2, 0, 1,
8, 42, 0, 1, 1, 48, 7, 0, 1, 8, 42, 3,
1, 1, 57, 7, 0, 1, 8, 42, 4, 1, 1, 48,
1, 2, 9, 3, 1, 2, 4, 1, 0, 1, 0, 48,
3, 0, 1, 5, 0, 0, 1, 0, 1, 3, 3, 0,
8, 8, 0, 11, 0, 0
};
typedef struct {
char opcode;
void(*handler)(int, int);
}vm_opcode;
char regs[5];
char * stack;
int vm_sp;
int vm_ip;
vm_opcode op_handler[HandlerN];
char buffer[60];
void MOV(int reg_index, int data); //1
void XOR(int reg_index0, int reg_index1); //2
void ADD(int reg_index0, int reg_index1); //3
void SUB(int reg_index0, int reg_index1); //4
void PUSH(int reg_index, int others); //5
void POP(int reg_index, int others); //6
void CMP(int reg_index0, int reg_index1); //7
void JUMP(int jmp_num, int others); //8
void PrintW(int nouse0, int use1); //9
void EXIT(int nouse0, int nouse1); //10
void NOP(int nouse0, int nouse1); //11
void MOV_INPUT(int reg_index0, int reg_index1); //12
void vm_init() {
/*初始化寄存器,栈等等*/
}
void dispatcher() {
while (true) {
if (vm_ip >= 138)
break;
for (int i = 0; i < HandlerN; i++) {
if (op_handler[i].opcode == opcodes[vm_ip])
op_handler[i].handler(opcodes[vm_ip + 1], opcodes[vm_ip + 2]);
}
}
}
void check() {
size_t len = strlen(enc_flag);
for (int i = 0; i < len; i++) {
if (stack[i] != enc_flag[i]) {
printf("wrong");
return;
}
}
printf("right");
}
int main(int argc, char * argv[]){
vm_init();
std::cout << "Please input your flag" << std::endl;
std::cin >> buffer;
regs[0] = (char)strlen(buffer);
dispatcher();
check();
}flag = r"flag{Th1s_1s_A_VerY_EzVM_And_Y0u_Are_S0_g00d}"
print(len(flag))
enc_flag = []
for x in flag:
i = ord(x)
if i >= ord('a') and i<= ord('z'):
enc_flag.append(i^71)
elif i >= ord('A') and i <= ord('Z'):
enc_flag.append(i^75)
elif i >= ord('0') and i<= ord('9'):
enc_flag.append(ord('0') + 9 - (i - ord('0')))
else:
enc_flag.append(i)
print(enc_flag)
d = [33, 43, 38, 32, 123, 31, 47, 56, 52, 95, 56, 52, 95, 10, 95, 29, 34, 53, 18, 95, 14, 61, 29, 6, 95, 10, 41, 35, 95, 18, 57, 50, 95, 10, 53, 34, 95, 24, 57, 95, 32, 57, 57, 35, 125]
f = ""
for i in d:
x1 = i ^ 71
x2 = i ^ 75
x3 = ord('0') + 9 - (i - ord('0'))
if x1 >= ord('a') and x1 <= ord('z'):
f += chr(x1)
elif x2 >= ord('A') and x2 <= ord('Z'):
f += chr(x2)
elif x3 >= ord('0') and x3 <= ord('9'):
f += chr(x3)
else:
f += chr(i)
print(f)CTF VM逆向
解题一般步骤:
分析VM结构 ==> 分析opcode ==> 编写parser ==> re算法
VM结构常见类型:
基于栈、基于队列、基于信号量
opcode:
与VM数据结构对应的指令 :push pop
运算指令:add、sub、mul
WxyVM1
程序无壳:main 函数如下:输入长度为24的 flag ,然后经过 sub_4005B6 函数处理后在check。
__int64 __fastcall main(int a1, char **a2, char **a3)
{
char v4; // [rsp+Bh] [rbp-5h]
int i; // [rsp+Ch] [rbp-4h]
puts("[WxyVM 0.0.1]");
puts("input your flag:");
scanf("%s", &input);
v4 = 1;
sub_4005B6(); // vm_run
if ( strlen(&input) != 24 )
v4 = 0;
for ( i = 0; i <= 23; ++i )
{
if ( *(&input + i) != dword_601060[i] ) // check
v4 = 0;
}
if ( v4 )
puts("correct");
else
puts("wrong");
return 0LL;
}sub_4005B6函数如下:没啥好说的,就是根据操作码对 input[v1] 进行处理,比较有意思的是 opcode[i] 只有1,2,3,所以case 4,5逻辑其实没啥用;其实也很好理解,因为这里对输入input处理了5000次,那么必定对input的每位处理了多次,而如果对input进行case 4,5逻辑的处理,那么反推是很困难的。
__int64 sub_4005B6()
{
__int64 result; // rax
int i; // [rsp+0h] [rbp-10h]
char v2; // [rsp+8h] [rbp-8h]
int v1; // [rsp+Ch] [rbp-4h]
for ( i = 0; i <= 14999; i += 3 ) // 指令长度为3
{
v2 = opcodes[i + 2]; // 第二个操作数
v1 = opcodes[i + 1]; // 第一个操作数
result = opcodes[i]; // 操作码
switch ( opcodes[i] )
{
case 1:
result = opcodes[i + 1];
*(&input + v1) += v2; //input[v1] += v2
break;
case 2:
result = opcodes[i + 1];
*(&input + v1) -= v2; //input[v1] -= v2
break;
case 3:
result = opcodes[i + 1];
*(&input + v1) ^= v2; //input[v1] ^= v2
break;
case 4:
result = opcodes[i + 1];
*(&input + v1) *= v2; //input[v1] *= v2
break;
case 5:
result = opcodes[i + 1];
*(&input + v1) ^= *(&input + opcodes[i + 2]); //input[v1] ^= input[v2]
break;
default:
continue;
}
}
return result;
}由于opcodes数组太大了,所以我们直接在IDA里面re
注意数据溢出的处理,最开始可能数据大一些,但是到后期数据会变得很小,所以我们在计算完成以后再使用
& 0xff来控制数据溢出。
import idautils
import idc
arr = [4294967236, 52, 34, 4294967217, 4294967251, 17, 4294967191, 7, 4294967259, 55, 4294967236, 6, 29, 4294967292, 91, 4294967277, 4294967192, 4294967263, 4294967188, 4294967256, 4294967219, 4294967172, 4294967244, 8]
opcodes = 0x6010c0
for i in range(14997,-1,-3):
v0 = get_wide_byte(opcodes + i)
v1 = get_wide_byte(opcodes + i + 1)
v2 = get_wide_byte(opcodes + i + 2)
if v0 == 1:
arr[v1] -= v2
if v0 == 2:
arr[v1] += v2
if v0 == 3:
arr[v1] ^= v2
for i in range(len(arr)):
arr[i] &= 0xff
print(''.join(map(chr, arr)))
#nctf{Embr4ce_Vm_j0in_R3}WxyVM2
这个题跟上个题很像,只是这个题加了很多无用代码来进行混淆,也可以叫做花指令;
但是仔细分析可以发现:最后循环是25次,对于byte_694100而言,它以字节为单位,所以最大为byte_694118;对于dword_694060而言,它以dword为单位,所以最大为dword_694120;
经过分析(肉眼观察),上面dword开头的数据都是大于dword_694120的,所以不会影响循环中byte_694100[i] 和dwrod_694060[i]的值,且byte开头的数据都会影响循环中byte_694100[i]的值;(这里dword_694060[i]的值不受影响是应该的,因为它是被check的对照字符串)
所以我们只需要把byte的数据提取出来,然后进行逆向即可;这里跟上面一样,对我们的输入byte_694100的每一位进行+,-,^操作
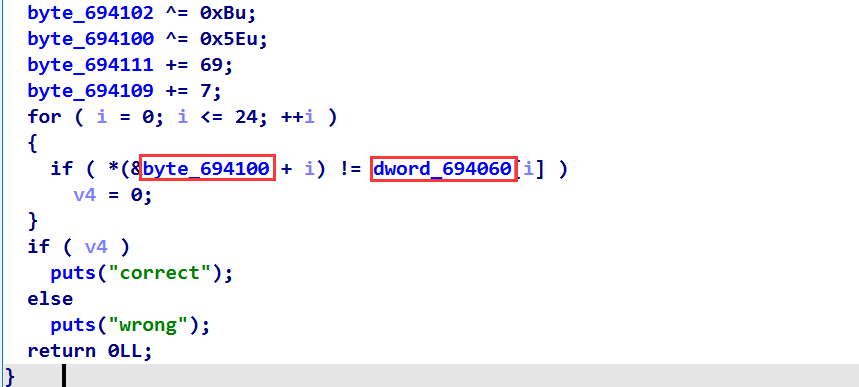
最终脚本如下:1.txt 文件中保存各种操作(这道题就是考察对数据的处理能力>_<)
import re
data = []
with open("Py\\1.txt", 'r') as f:
for line in f:
if "byte_6941" in line:
if '--' in line or '++' in line:
x = re.findall(r"(.+?);", line.rsplit()[0])
tmp = [str(x[0][11:])]
if '--' in line: tmp.append('+')
else: tmp.append('-')
tmp.append('1')
data.append(tmp)
else:
x = line.rsplit()
tmp = re.findall(r"byte_6941(.+)", x[0])
if x[1][0] == '-': tmp.append('+')
elif x[1][0] == '+': tmp.append('-')
else: tmp.append(x[1][0])
if x[2][-2:-1] == 'u': tmp.append(x[2][:-2])
else: tmp.append(x[2][:-1])
data.append(tmp)
enc_flag = [ 4294967232,4294967173,4294967289,108,4294967266,20,4294967227,4294967268,13,89,28,35,4294967176,110,4294967195,4294967242,4294967226,92,55,4294967295,72,4294967256,31,4294967211,4294967205 ]
for i in data[::-1]:
l = "enc_flag[int(i[0], 16)]" + i[1]
if '0x' in i[2]: l += "int(i[2], 16)"
else: l += i[2]
enc_flag[int(i[0], 16)] = eval(l)
for i in range(len(enc_flag)):
enc_flag[i] &= 0xff
print(''.join(map(chr, enc_flag)))
#nctf{th3_vM_w1th0ut_dAta}[网鼎杯 2020 青龙组]singal
vm_operad已经提示是VM了,dword_403040的前114个dword是opcode
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v4[117]; // [esp+18h] [ebp-1D4h] BYREF
__main();
qmemcpy(v4, &dword_403040, 0x1C8u);
vm_operad(v4, 114);
puts("good,The answer format is:flag {}");
return 0;
}vm_operad通过swicth进行各种操作:这个程序很有意思,注意注意:这里input数组的大小是200,程序把加密后的输入存放在了input[100]之后的位置,其他的逻辑都很简单
int __cdecl vm_operad(int *opcodes, int len)
{
int result; // eax
char input[200]; // [esp+13h] [ebp-E5h] BYREF
char reg; // [esp+DBh] [ebp-1Dh]
int v5; // [esp+DCh] [ebp-1Ch]
int v6; // [esp+E0h] [ebp-18h]
int v7; // [esp+E4h] [ebp-14h]
int i; // [esp+E8h] [ebp-10h]
int vm_ip; // [esp+ECh] [ebp-Ch]
vm_ip = 0;
i = 0;
v7 = 0;
v6 = 0;
v5 = 0;
while ( 1 )
{
result = vm_ip;
if ( vm_ip >= len )
return result;
switch ( opcodes[vm_ip] )
{
case 1:
input[v6 + 100] = reg; //把处理后的字符存放在input[100]之后
++vm_ip;
++v6;
++i;
break;
case 2: //加法
reg = opcodes[vm_ip + 1] + input[i];
vm_ip += 2;
break;
case 3: //减法
reg = input[i] - LOBYTE(opcodes[vm_ip + 1]);
vm_ip += 2;
break;
case 4://异或
reg = opcodes[vm_ip + 1] ^ input[i];
vm_ip += 2;
break;
case 5://乘法
reg = opcodes[vm_ip + 1] * input[i];
vm_ip += 2;
break;
case 6: //nop
++vm_ip;
break;
case 7: //check,input[100]之后是对我们输入处理后的字符
if ( input[v7 + 100] != opcodes[vm_ip + 1] )
{
printf("what a shame...");
exit(0);
}
++v7;
vm_ip += 2;
break;
case 8: //赋值
input[v5] = reg;
++vm_ip;
++v5;
break;
case 10: //读取输入
read(input);
++vm_ip;
break;
case 11: //减一
reg = input[i] - 1;
++vm_ip;
break;
case 12://加一
reg = input[i] + 1;
++vm_ip;
break;
default:
continue;
}
}
}提取opcode
import idc
import idautils
addr = 0x00403040
arr = []
for i in range(114):
tmp = get_wide_dword(addr)
arr.append(tmp)
addr += 4
print(arr)
"""
[10, 4, 16, 8, 3, 5, 1, 4, 32, 8, 5, 3, 1, 3, 2, 8, 11, 1, 12, 8, 4, 4, 1, 5, 3, 8, 3, 33, 1, 11, 8, 11, 1, 4, 9, 8, 3, 32, 1, 2, 81, 8, 4, 36, 1, 12, 8, 11, 1, 5, 2, 8, 2, 37, 1, 2, 54, 8, 4, 65, 1, 2, 32, 8, 5, 1, 1, 5, 3, 8, 2, 37, 1, 4, 9, 8, 3, 32, 1, 2, 65, 8, 12, 1, 7, 34, 7, 63, 7, 52, 7, 50, 7, 114, 7, 51, 7, 24, 7, 4294967207, 7, 49, 7, 4294967281, 7, 40, 7, 4294967172, 7, 4294967233, 7, 30, 7, 122]
"""把 opcode 转换为对应的操作,然后可以得到整个流程,>_<它这个好像没有算法,所以就手动一个一个字符的算;当然其实也是有一定规律的,那就是每个字符都会依次进行两步处理,且都不相互影响,所以我们可以把opcodes分成15组,然后一个字符一个字符的爆破,这样速度非常快,这里爆破脚本直接拿的绿冰壶大佬的;当然也可以直接angr秒了
opcodes = [10, 4, 16, 8, 3, 5, 1, 4, 32, 8, 5, 3,
1, 3, 2, 8, 11, 1, 12, 8, 4, 4, 1, 5, 3, 8, 3, 33,
1, 11, 8, 11, 1, 4, 9, 8, 3, 32, 1, 2, 81, 8, 4, 36,
1, 12, 8, 11, 1, 5, 2, 8, 2, 37, 1, 2, 54, 8, 4, 65,
1, 2, 32, 8, 5, 1, 1, 5, 3, 8, 2, 37, 1, 4, 9, 8, 3,
32, 1, 2, 65, 8, 12, 1, 7, 34, 7, 63, 7, 52, 7, 50, 7,
114, 7, 51, 7, 24, 7, 4294967207, 7, 49, 7, 4294967281,
7, 40, 7, 4294967172, 7, 4294967233, 7, 30, 7, 122]
func = {
1:[1,'data[k] = reg;k++,i++'],
2:[2, 'reg = opcodes[vm_ip + 1] + input[i]'],
3:[2, 'reg = input[i] - LOBYTE(opcodes[vm_ip+1])'],
4:[2, 'reg = opcodes[vm_ip + 1] ^ input[i]'],
5:[2, 'reg = opcodes[vm_ip + 1] * input[i]'],
6:[1, 'nop'],
7:[2, 'check:data[n] == opcodes[vm_ip + 1];n++'],
8:[1, 'input[v5] = reg;v5++'],
10:[1, 'read(input)'],
11:[1, 'reg = input[i] - 1'],
12:[1, 'reg = input[i] + 1']
}
vm_ip = 0
count = 0
data = []
while 1:
if vm_ip >= 114: break
tmp = func[opcodes[vm_ip]]
count += 1
if tmp[0] == 1:
print(f'[{count}]:', end='')
print(tmp[1])
vm_ip += 1
elif opcodes[vm_ip] == 7: #这里都是check,就不需要输出了,把checK的字符存放在data中
data.append(opcodes[vm_ip+1]&0xff)
vm_ip += 2
else:
print(f'[{count}]:', end='')
print(tmp[1], "- -[opcodes[vm_ip+1]]:", opcodes[vm_ip+1])
vm_ip += 2
print(data)
"""
手动解析>_<,其实挺简单的,都是些加减异或操作,但是就是老是看错,所以还是爆破吧
而且手动解析后也发现每个字符确实也都只进行了两步操作
[1]:read(input)
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[2]:reg = opcodes[vm_ip + 1] ^ input[i] - -[opcodes[vm_ip+1]]: 16
[3]:input[v5] = reg;v5++
[4]:reg = input[i] - LOBYTE(opcodes[vm_ip+1]) - -[opcodes[vm_ip+1]]: 5
[5]:data[k] = reg;k++,i++
data[0] = 16 ^ input[0] - (5&0xff)
input[0] = (data[0] + (5&0xff)) ^ 16 = '7'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[6]:reg = opcodes[vm_ip + 1] ^ input[i] - -[opcodes[vm_ip+1]]: 32
[7]:input[v5] = reg;v5++
[8]:reg = opcodes[vm_ip + 1] * input[i] - -[opcodes[vm_ip+1]]: 3
[9]:data[k] = reg;k++,i++
data[1] = 3 * (32 ^ input[1])
input[1] = (data[1] / 3) ^ 32 = '5'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[10]:reg = input[i] - LOBYTE(opcodes[vm_ip+1]) - -[opcodes[vm_ip+1]]: 2
[11]:input[v5] = reg;v5++
[12]:reg = input[i] - 1
[13]:data[k] = reg;k++,i++
data[2] = input[2] - (2&0xff) - 1
input[2] = data[2] + (2&0xff) + 1 = '7'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[14]:reg = input[i] + 1
[15]:input[v5] = reg;v5++
[16]:reg = opcodes[vm_ip + 1] ^ input[i] - -[opcodes[vm_ip+1]]: 4
[17]:data[k] = reg;k++,i++
data[3] = 4 ^ (input[3] + 1)
input[3] = data[3] ^ 4 - 1 = '5'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[18]:reg = opcodes[vm_ip + 1] * input[i] - -[opcodes[vm_ip+1]]: 3
[19]:input[v5] = reg;v5++
[20]:reg = input[i] - LOBYTE(opcodes[vm_ip+1]) - -[opcodes[vm_ip+1]]: 33
[21]:data[k] = reg;k++,i++
data[4] = 3 * input[4] - 33&0xff
input = (data[4] + 33&0xff) / 3 = '1'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[22]:reg = input[i] - 1
[23]:input[v5] = reg;v5++
[24]:reg = input[i] - 1
[25]:data[k] = reg;k++,i++
data[5] = input[5] - 2
input[5] = data[5] + 2 = '5'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[26]:reg = opcodes[vm_ip + 1] ^ input[i] - -[opcodes[vm_ip+1]]: 9
[27]:input[v5] = reg;v5++
[28]:reg = input[i] - LOBYTE(opcodes[vm_ip+1]) - -[opcodes[vm_ip+1]]: 32
[29]:data[k] = reg;k++,i++
data[6] = 9 ^ input[6] - 32&0xff
input[6] = '1'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[30]:reg = opcodes[vm_ip + 1] + input[i] - -[opcodes[vm_ip+1]]: 81
[31]:input[v5] = reg;v5++
[32]:reg = opcodes[vm_ip + 1] ^ input[i] - -[opcodes[vm_ip+1]]: 36
[33]:data[k] = reg;k++,i++
data[7] = 36 ^ (81 + input[7])
input[7] = '2'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[34]:reg = input[i] + 1
[35]:input[v5] = reg;v5++
[36]:reg = input[i] - 1
[37]:data[k] = reg;k++,i++
data[8] = (input[8] + 1) - 1
input[8] = '1'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[38]:reg = opcodes[vm_ip + 1] * input[i] - -[opcodes[vm_ip+1]]: 2
[39]:input[v5] = reg;v5++
[40]:reg = opcodes[vm_ip + 1] + input[i] - -[opcodes[vm_ip+1]]: 37
[41]:data[k] = reg;k++,i++
data[9] = 37 + (2 * input[9])
input[9] = 'f'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[42]:reg = opcodes[vm_ip + 1] + input[i] - -[opcodes[vm_ip+1]]: 54
[43]:input[v5] = reg;v5++
[44]:reg = opcodes[vm_ip + 1] ^ input[i] - -[opcodes[vm_ip+1]]: 65
[45]:data[k] = reg;k++,i++
data[10] = 65 ^ (54 + input[10])
input[10] = '3'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[46]:reg = opcodes[vm_ip + 1] + input[i] - -[opcodes[vm_ip+1]]: 32
[47]:input[v5] = reg;v5++
[48]:reg = opcodes[vm_ip + 1] * input[i] - -[opcodes[vm_ip+1]]: 1
[49]:data[k] = reg;k++,i++
data[11] = 1 * (32 + input[11])
input[11] = 'd'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[50]:reg = opcodes[vm_ip + 1] * input[i] - -[opcodes[vm_ip+1]]: 3
[51]:input[v5] = reg;v5++
[52]:reg = opcodes[vm_ip + 1] + input[i] - -[opcodes[vm_ip+1]]: 37
[53]:data[k] = reg;k++,i++
data[12] = 37 + (3 * input[12])
input[12] = '4'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[54]:reg = opcodes[vm_ip + 1] ^ input[i] - -[opcodes[vm_ip+1]]: 9
[55]:input[v5] = reg;v5++
[56]:reg = input[i] - LOBYTE(opcodes[vm_ip+1]) - -[opcodes[vm_ip+1]]: 32
[57]:data[k] = reg;k++,i++
data[13] = (9 ^ input[13]) - 32&0xff
input[13] = '7'
data = [34, 63, 52, 50, 114, 51, 24, 167, 49, 241, 40, 132, 193, 30, 122]
[58]:reg = opcodes[vm_ip + 1] + input[i] - -[opcodes[vm_ip+1]]: 65
[59]:input[v5] = reg;v5++
[60]:reg = input[i] + 1
[61]:data[k] = reg;k++,i++
data[14] = (65 + input[14]) + 1
input[14] = '8'
所以输入为: 757515121f3d478
flag: flag{757515121f3d478}
"""
爆破脚本
encrypts = [0x22, 0x3F, 0x34, 0x32, 0x72, 0x33, 0x18, 0xA7, 0x31, 0xF1, 0x28, 0x84, 0xC1, 0x1E, 0x7A]
data = [[4, 0x10, 8, 3, 5, 1]
, [4, 0x20, 8, 5, 3, 1]
, [3, 2, 8, 0x0B, 1]
, [0x0C, 8, 4, 4, 1]
, [5, 3, 8, 3, 0x21, 1]
, [0x0B, 8, 0x0B, 1]
, [4, 9, 8, 3, 0x20, 1]
, [2, 0x51, 8, 4, 0x24, 1]
, [0x0C, 8, 0x0B, 1]
, [5, 2, 8, 2, 0x25, 1]
, [2, 0x36, 8, 4, 0x41, 1]
, [2, 0x20, 8, 5, 1, 1]
, [5, 3, 8, 2, 0x25, 1]
, [4, 9, 8, 3, 0x20, 1]
, [2, 0x41, 8, 0x0C, 1]]
for_each = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '1', '2', '3', '4', '5', '6', '7', '8', '9', '0']
def encrypted(c, li):
# print(li)
x = 0
while x < len(li):
if li[x] == 2:
c = c + li[x + 1]
x += 2
elif li[x] == 3:
c = c - li[x + 1]
x += 2
elif li[x] == 4:
c = c ^ li[x + 1]
x += 2
elif li[x] == 5:
c = c * li[x + 1]
x += 2
elif li[x] == 11:
c = c - 1
x += 1
elif li[x] == 12:
c = c + 1
x += 1
elif li[x] == 8:
x += 1
elif li[x] == 1:
break
res = c
return res
if __name__ == '__main__':
flag = ''
for x in range(len(encrypts)):
for i in for_each:
tmp = encrypted(ord(i), data[x])
if tmp == encrypts[x]:
flag += i
break
else:
continue
print('flag{%s}' % flag)angr脚本
import angr
proj = angr.Project('./signal.exe', auto_load_libs = False)
init_state = proj.factory.entry_state()
sim = proj.factory.simulation_manager(init_state)
sim.explore(find = 0x0040179E, avoid = 0x004016E6)
found_states = sim.found
if found_states:
ans = found_states[0].posix.dumps(0)
print(ans)
else:
print("Cant't find solution!")总结
对于比较简单的VM逆向题,直接把opcodes找出来,然后分析每个handler的功能,最后把opcodes的流程对照handler给捋清楚,然后直接肝就完了。

